Numpy 是一个开源的 Python 科学计算库,用于快速处理任意维度的数组。Numpy 支持常见的数组和矩阵操作,对于同样的数值计算任务,使用 NumPy 不仅代码要简洁的多,而且 NumPy 在性能上也远远优于原生 Python,至少是一到两个数量级的差距,而且数据量越大,NumPy 的优势就越明显。
NumPy 最为核心的数据类型是ndarray,使用ndarray可以处理一维、二维和多维数组,该对象相当于是一个快速而灵活的大数据容器。NumPy 底层代码使用 C 语言编写,解决了 GIL 的限制,ndarray在存取数据的时候,数据与数据的地址都是连续的,这确保了可以进行高效率的批量操作,性能上远远优于 Python 中的list;另一方面ndarray对象提供了更多的方法来处理数据,尤其获取数据统计特征的方法,这些方法也是 Python 原生的list没有的。
准备工作
-
启动 JupyterLab
1
jupyter lab
提示:在启动 JupyterLab 之前,建议先安装好数据分析相关依赖项,包括之前提到的三大神器以及相关依赖项。如果使用 Anaconda,则无需单独安装,可以通过 Anaconda 的 Navigator 来启动。
-
导入
1
2
3import numpy as np
import pandas as pd
import matplotlib.pyplot as plt说明:如果已经启动了 JupyterLab 但尚未安装相关依赖库,例如尚未安装
numpy,可以在单元格中输入%pip install numpy并运行该单元格来安装 NumPy。当然,我们也可以在单元格中输入%pip install numpy pandas matplotlib把 Python 数据分析三个核心的三方库都安装上。注意上面的代码,我们不仅导入了 NumPy,还将 pandas 和 matplotlib 库一并导入了。
创建数组对象
创建ndarray对象有很多种方法,下面我们介绍一些常用的方法。
方法一:使用array函数,通过list创建数组对象
代码:
1 | array1 = np.array([1, 2, 3, 4, 5]) |
输出:
1 | array([1, 2, 3, 4, 5]) |
代码:
1 | array2 = np.array([[1, 2, 3], [4, 5, 6]]) |
输出:
1 | array([[1, 2, 3], |
方法二:使用arange函数,指定取值范围和跨度创建数组对象
代码:
1 | array3 = np.arange(0, 20, 2) |
输出:
1 | array([ 0, 2, 4, 6, 8, 10, 12, 14, 16, 18]) |
方法三:使用linspace函数,用指定范围和元素个数创建数组对象,生成等差数列
代码:
1 | array4 = np.linspace(-1, 1, 11) |
输出:
1 | array([-1. , -0.8, -0.6, -0.4, -0.2, 0. , 0.2, 0.4, 0.6, 0.8, 1. ]) |
方法四:使用logspace函数,生成等比数列
代码:
1 | array5 = np.logspace(1, 10, num=10, base=2) |
注意:等比数列的起始值是$21$,等比数列的终止值是$2{10}$,
num是元素的个数,base就是底数。
输出:
1 | array([ 2., 4., 8., 16., 32., 64., 128., 256., 512., 1024.]) |
方法五:通过fromstring函数从字符串提取数据创建数组对象
代码:
1 | array6 = np.fromstring('1, 2, 3, 4, 5', sep=',', dtype='i8') |
输出:
1 | array([1, 2, 3, 4, 5]) |
方法六:通过fromiter函数从生成器(迭代器)中获取数据创建数组对象
代码:
1 | def fib(how_many): |
输出:
1 | array([ 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, |
方法七:使用numpy.random模块的函数生成随机数创建数组对象
产生10个$[0, 1)$范围的随机小数,代码:
1 | array8 = np.random.rand(10) |
输出:
1 | array([0.45556132, 0.67871326, 0.4552213 , 0.96671509, 0.44086463, |
产生10个$[1, 100)$范围的随机整数,代码:
1 | array9 = np.random.randint(1, 100, 10) |
输出:
1 | array([29, 97, 87, 47, 39, 19, 71, 32, 79, 34]) |
产生20个$\small{\mu=50}$,$\small{\sigma=10}$的正态分布随机数,代码:
1 | array10 = np.random.normal(50, 10, 20) |
输出:
1 | array([55.04155586, 46.43510797, 20.28371158, 62.67884053, 61.23185964, |
产生$[0, 1)$范围的随机小数构成的3行4列的二维数组,代码:
1 | array11 = np.random.rand(3, 4) |
输出:
1 | array([[0.54017809, 0.46797771, 0.78291445, 0.79501326], |
产生$[1, 100)$范围的随机整数构成的三维数组,代码:
1 | array12 = np.random.randint(1, 100, (3, 4, 5)) |
输出:
1 | array([[[94, 26, 49, 24, 43], |
方法八:创建全0、全1或指定元素的数组
使用zeros函数,代码:
1 | array13 = np.zeros((3, 4)) |
输出:
1 | array([[0., 0., 0., 0.], |
使用ones函数,代码:
1 | array14 = np.ones((3, 4)) |
输出:
1 | array([[1., 1., 1., 1.], |
使用full函数,代码:
1 | array15 = np.full((3, 4), 10) |
输出:
1 | array([[10, 10, 10, 10], |
方法九:使用eye函数创建单位矩阵
代码:
1 | np.eye(4) |
输出:
1 | array([[1., 0., 0., 0.], |
方法十:读取图片获得对应的三维数组
代码:
1 | array16 = plt.imread('res/guido.jpg') |
输出:
1 | array([[[ 36, 33, 28], |
说明:上面的代码读取了当前路径下
res目录中名为guido.jpg的图片文件,计算机系统中的图片通常由若干行若干列的像素点构成,而每个像素点又是由红绿蓝三原色构成的,刚好可以用三维数组来表示。读取图片用到了matplotlib库的imread函数。
数组对象的属性
size属性:获取数组元素个数。
代码:
1 | array17 = np.arange(1, 100, 2) |
输出:
1 | 1125000 |
shape属性:获取数组的形状。
代码:
1 | print(array16.shape) |
输出:
1 | (750, 500, 3) |
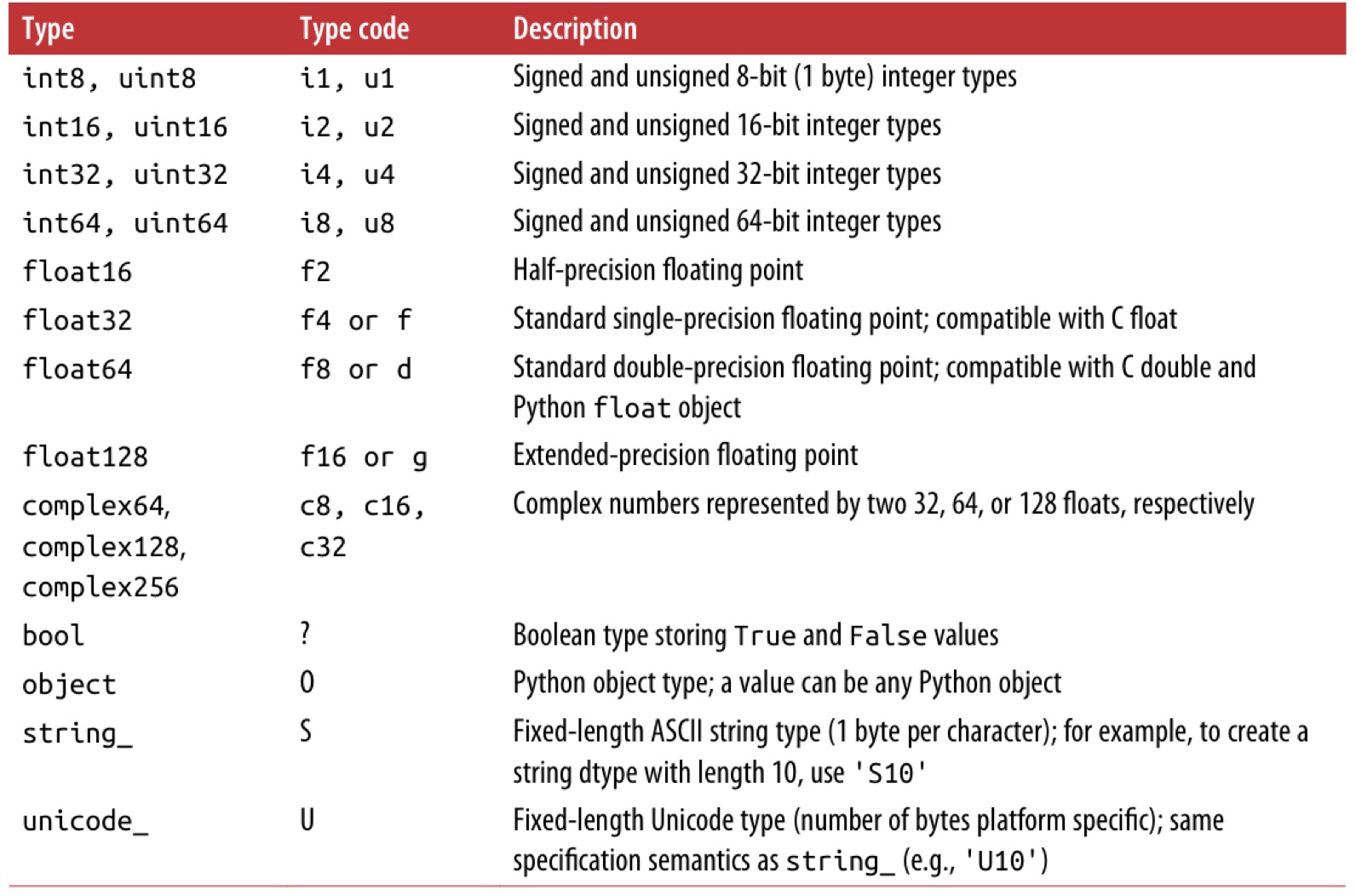
dtype属性:获取数组元素的数据类型。
代码:
1 | print(array16.dtype) |
输出:
1 | uint8 |
ndarray对象元素的数据类型可以参考如下所示的表格。
ndim属性:获取数组的维度。
代码:
1 | print(array16.ndim) |
输出:
1 | 3 |
itemsize属性:获取数组单个元素占用内存空间的字节数。
代码:
1 | print(array16.itemsize) |
输出:
1 | 1 |
nbytes属性:获取数组所有元素占用内存空间的字节数。
代码:
1 | print(array16.nbytes) |
输出:
1 | 1125000 |
数组的索引运算
和 Python 中的列表类似,NumPy 的ndarray对象可以进行索引和切片操作,通过索引可以获取或修改数组中的元素,通过切片操作可以取出数组的一部分,我们把切片操作也称为切片索引。
普通索引
类似于 Python 中list类型的索引运算。
代码:
1 | array19 = np.arange(1, 10) |
输出:
1 | 1 9 |
代码:
1 | array20 = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) |
输出:
1 | array([7, 8, 9]) |
代码:
1 | print(array20[0][0]) |
输出:
1 | 1 |
代码:
1 | print(array20[1][1]) |
输出:
1 | 5 |
代码:
1 | array20[1][1] = 10 |
输出:
1 | array([[ 1, 2, 3], |
代码:
1 | array20[1] = [10, 11, 12] |
输出:
1 | array([[ 1, 2, 3], |
切片索引
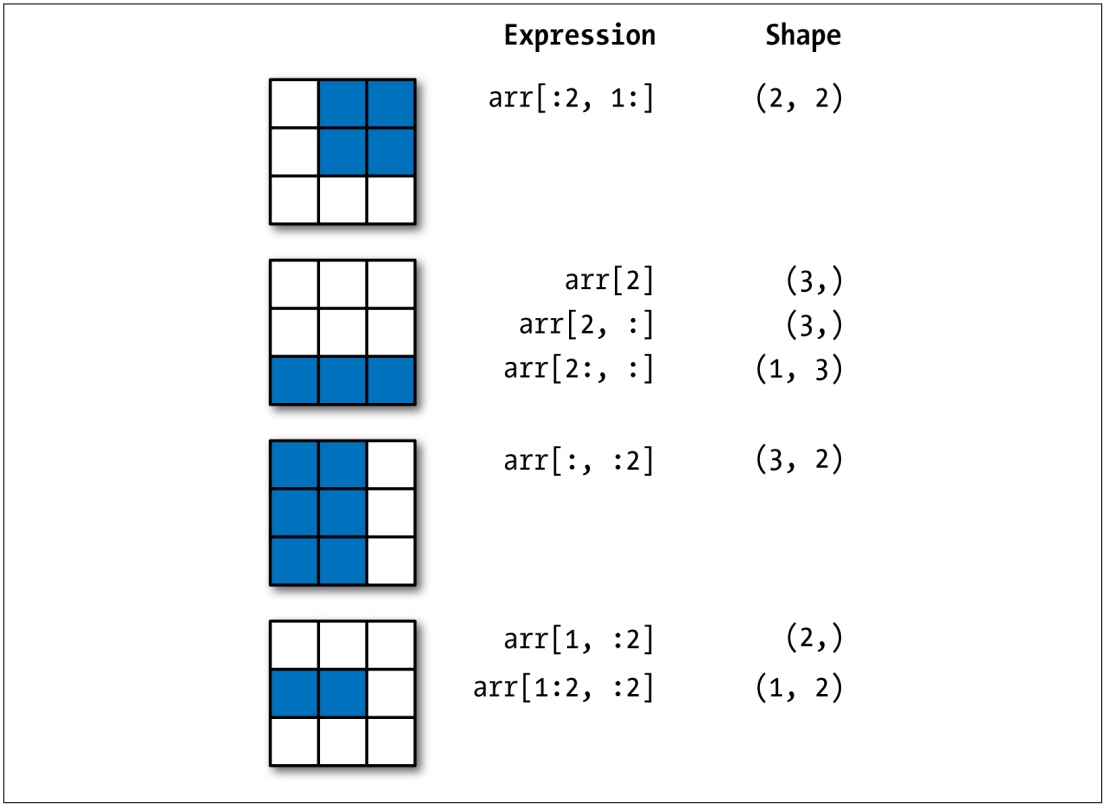
切片索引是形如[开始索引:结束索引:跨度]的语法,通过指定开始索引(默认值无穷小)、结束索引(默认值无穷大)和跨度(默认值1),从数组中取出指定部分的元素并构成新的数组。因为开始索引、结束索引和步长都有默认值,所以它们都可以省略,如果不指定步长,第二个冒号也可以省略。一维数组的切片运算跟 Python 中的list类型的切片非常类似,此处不再赘述,二维数组的切片可以参考下面的代码,相信非常容易理解。
代码:
1 | array20[:2, 1:] |
输出:
1 | array([[ 2, 3], |
代码:
1 | array20[2, :] |
输出:
1 | array([7, 8, 9]) |
代码:
1 | array20[2:, :] |
输出:
1 | array([[7, 8, 9]]) |
代码:
1 | array20[:, :2] |
输出:
1 | array([[ 1, 2], |
代码:
1 | array20[::2, ::2] |
输出:
1 | array([[1, 3], |
代码:
1 | array20[::-2, ::-2] |
输出:
1 | array([[9, 7], |
关于数组的索引和切片运算,大家可以通过下面的两张图来增强印象,这两张图来自《利用Python进行数据分析》一书,它是 pandas 库的作者 Wes McKinney 撰写的 Python 数据分析领域的经典教科书,有兴趣的读者可以购买和阅读原书。
图1:二维数组的普通索引
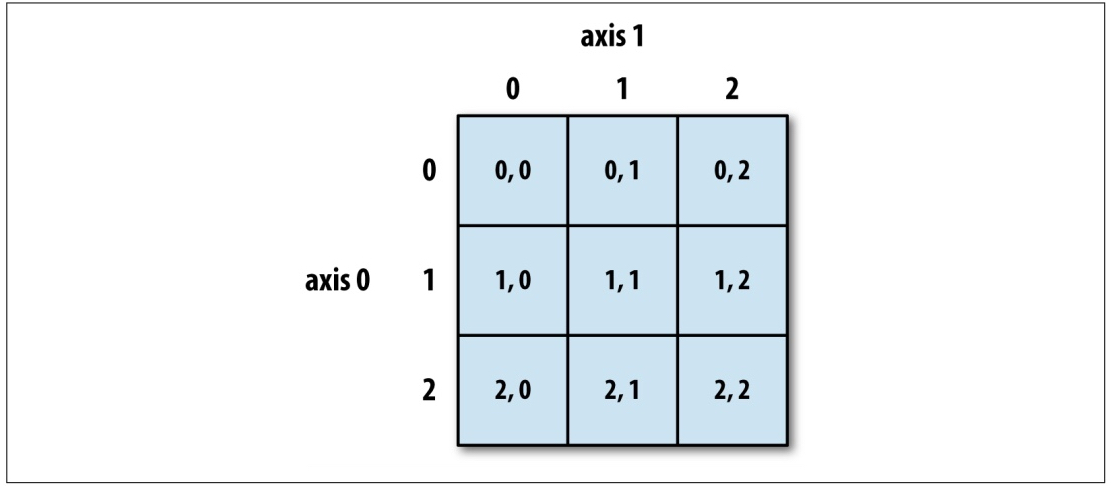
图2:二维数组的切片索引
花式索引
花式索引是用保存整数的数组充当一个数组的索引,这里所说的数组可以是 NumPy 的ndarray,也可以是 Python 中list、tuple等可迭代类型,可以使用正向或负向索引。
代码:
1 | array19[[0, 1, 1, -1, 4, -1]] |
输出:
1 | array([1, 2, 2, 9, 5, 9]) |
代码:
1 | array20[[0, 2]] |
输出:
1 | array([[1, 2, 3], |
代码:
1 | array20[[0, 2], [1, 2]] |
输出:
1 | array([2, 9]) |
代码:
1 | array20[[0, 2], 1] |
输出:
1 | array([2, 8]) |
布尔索引
布尔索引就是通过保存布尔值的数组充当一个数组的索引,布尔值为True的元素保留,布尔值为False的元素不会被选中。布尔值的数组可以手动构造,也可以通过关系运算来产生。
代码:
1 | array19[[True, True, False, False, True, False, False, True, True]] |
输出:
1 | array([1, 2, 5, 8, 9]) |
代码:
1 | array19 > 5 |
输出:
1 | array([False, False, False, False, False, True, True, True, True]) |
代码:
1 | ~(array19 > 5) |
输出:
1 | array([ True, True, True, True, True, False, False, False, False]) |
说明:
~运算符可以对布尔数组中的布尔值进行逻辑取反,也就是原来的True会变成False,原来的False会变成True。
代码:
1 | array19[array20 > 5] |
输出:
1 | array([6, 7, 8, 9]) |
代码:
1 | array19 % 2 == 0 |
输出:
1 | array([False, True, False, True, False, True, False, True, False]) |
代码:
1 | array19[array20 % 2 == 0] |
输出:
1 | array([2, 4, 6, 8]) |
代码:
1 | (array19 > 5) & (array19 % 2 == 0) |
输出:
1 | array([False, False, False, False, False, True, False, True, False]) |
说明:
&运算符可以作用于两个布尔数组,如果两个数组对应元素都是True,那么运算的结果就是True,否则就是False,该运算符的运算规则类似于 Python 中的and运算符,只不过作用的对象是两个布尔数组。
代码:
1 | array19[(array19 > 5) & (array19 % 2 == 0)] |
输出:
1 | array([6, 8]) |
代码:
1 | array19[(array19 > 5) | (array19 % 2 == 0)] |
输出:
1 | array([2, 4, 6, 7, 8, 9]) |
说明:
|运算符可以作用于两个布尔数组,如果两个数组对应元素都是False,那么运算的结果就是False,否则就是True,该运算符的运算规则类似于 Python 中的or运算符,只不过作用的对象是两个布尔数组。
代码:
1 | array20[array21 % 2 != 0] |
输出:
1 | array([1, 3, 5, 7, 9]) |
关于索引运算需要说明的是,切片索引虽然创建了新的数组对象,但是新数组和原数组共享了数组中的数据,简单的说,无论你通过新数组对象或原数组对象修改数组中的数据,修改的其实是内存中的同一块数据。花式索引和布尔索引也会创建新的数组对象,而且新数组复制了原数组的元素,新数组和原数组并不是共享数据的关系,这一点可以查看数组对象的base属性,有兴趣的读者可以自行探索。
案例:通过数组切片处理图像
学习基础知识总是比较枯燥且没有成就感的,所以我们还是来个案例为大家演示下上面学习的数组索引和切片操作到底有什么用。前面我们说到过,可以用三维数组来表示图像,那么通过图像对应的三维数组进行操作,就可以实现对图像的处理,如下所示。
读入图片创建三维数组对象。
1 | guido_image = plt.imread('guido.jpg') |

对数组的0轴进行反向切片,实现图像的垂直翻转。
1 | plt.imshow(guido_image[::-1]) |

对数组的1轴进行反向切片,实现图像的水平翻转。
1 | plt.imshow(guido_image[:,::-1]) |

通过切片操作实现抠图,将吉多大叔的头抠出来。
1 | plt.imshow(guido_image[30:350, 90:300]) |

通过切片操作实现降采样。
1 | plt.imshow(guido_image[::10, ::10]) |
