〇、什么是C语言
C语言是一种通用的、过程性的、高级编程语言。它由美国计算机科学家丹尼斯·里奇(Dennis Ritchie)在20世纪70年代初期在贝尔实验室开发。C语言具有高度的可移植性,广泛用于系统编程、应用程序开发、嵌入式系统等领域。以下是C语言的一些特点:
- 过程性编程: C语言是一种过程性的编程语言,强调程序的执行过程,通过函数调用来组织和结构化程序。
- 中级语言: C语言同时具备高级语言和低级语言的特性,允许直接访问计算机内存,并提供了高级抽象的编程结构。
- 可移植性: C语言的代码可以在不同的平台上编写一次,然后在不同的计算机系统上进行编译和运行,而无需做大量的修改。
- 强大的表达能力: C语言提供了丰富的运算符、控制结构和数据类型,使程序员能够灵活地表达各种计算和控制逻辑。
- 标准化: C语言有一套由国际标准化组织(ISO)定义的标准,目前最新的标准是ISO C18。这使得不同编译器能够遵循相同的规范,提高了代码的可移植性。
- 广泛应用: C语言被广泛应用于系统编程、操作系统开发、嵌入式系统、游戏开发、数据库系统、网络编程等各个领域。
- 简洁而高效: C语言的语法相对简洁,同时它产生的机器代码非常高效,这使得C语言在开发底层系统和对性能要求较高的应用中得到了广泛的应用。
编译型语言:程序需要啊编译器编译后才能执行,C、C++
解释型语言:代码需要解析器解析后才能执行,python、shell
C语言是许多编程语言的基础,如C++、C#、Objective-C等,它对程序员的思维和编程习惯产生了深远的影响。
一、第一个C语言程序
template.c
1 |
|
养成良好的编程习惯
源码格式对于程序的可读性和维护性非常重要。良好的代码风格和格式可以使代码更易于理解。以下是一些常见的C语言源码格式约定:
-
缩进: 使用合适的缩进来表示代码块的层次结构。通常,一个缩进等于两个或四个空格。缩进使得代码块的层次关系更加清晰。
1
2
3
4
5
6if (condition) {
// 代码块
for (int i = 0; i < 10; ++i) {
// 嵌套的代码块
}
} -
空格: 在适当的地方使用空格,例如在运算符周围和逗号后面。
1
2int sum = a + b;
int result = addNumbers(3, 4); -
换行: 在适当的位置使用换行符,使代码在屏幕上不需要水平滚动。通常,在函数之间和代码块之间留有一些空行
1
2
3
4
5
6
7void function1() {
// 代码
}
void function2() {
// 代码
} -
注释: 使用注释来解释代码的目的、思路或特殊处理。写代码一定要写注释啊!
1
2
3
4
5
6// 这是一个单行注释
/*
* 这是一个多行注释
* 可以跨越多行
*/ -
命名规范: 使用有意义的变量和函数名,并遵循一致的命名规范。通常使用驼峰命名法或下划线命名法。
1
2
3int calculateSum(int a, int b) {
// 代码
} -
头文件保护: 使用头文件保护宏,防止头文件被重复包含。
1
2
3
4
5
6
// 头文件内容
.h 和 .c
在C语言中,通常将程序分为头文件(.h)和源文件(.c)两种类型。这是一种常见的组织代码的方式,有助于提高代码的模块化、可读性和可维护性。
-
头文件(.h):
- 头文件包含了函数、变量的声明、宏定义以及其他需要在多个源文件中共享的内容。
- 通常包含了函数原型(函数声明)和结构体/类的定义,但不包含函数的具体实现。
- 头文件使用
.h作为文件扩展名。
例子:
example.h1
2
3
4
5
6
7
// 函数声明
int add(int a, int b); -
源文件(.c):
- 源文件包含了函数和变量的具体实现。
- 包含了头文件以获取函数原型,然后实现具体的功能。
- 通常一个源文件对应一个编译单元,可以编译成一个目标文件。
- 源文件使用
.c作为文件扩展名。
例子:
example.c1
2
3
4
5
6
// 函数实现
int add(int a, int b) {
return a + b;
}
二、gcc编译器
gcc 是GNU Compiler Collection(GNU编译器集合)的缩写,是一套自由软件基金会(Free Software Foundation)开发的编译器套件。gcc 主要用于编译C、C++、Fortran等程序语言,并支持多种不同的平台和操作系统。
只要程序发生过修改,就需要重新gcc编译生成新的可执行文件
一步编译
编译直接生成可执行程序,运行可执行程序即可
1 | gcc xxx.c ---->默认生成一个名为a.out的可执行文件 |
分步编译ESc–>iso
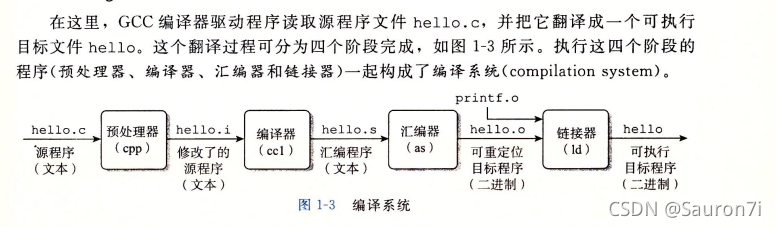
预处理 ----> 编译 ----> 汇编 ----> 链接
预处理: 展开头文件,替换宏定义,删除注释,不会检查语法错误,生成编译文件
1 | gcc -E xxx.c -o xxx.i |
编译: 检查语法正确性,生成汇编文件 `
1 | gcc -S xxx.i -o xxx.s |
汇编: 将汇编文件生成目标文件
1 | gcc **-c** xxx.s -o xxx.o |
链接: 链接到程序所需的库,生成可执行文件
1 | gcc xxx.o -o hello |
运行程序:
1 | ./hello |
三、计算机中的数据存储
计算机中的存储单位
比特(英语:bit,亦称二进制位)指二进制中的一位,是信息的最小单位。bit是binary digit(二进制数位)的混成词,由数学家John Wilder Tukey提出(提出时间可能是1946年,但有资料称1943年就提出了)。这个术语第一次被正式使用,是在香农著名的论文《通信的数学理论》(A Mathematical Theory of Communication)第1页中。——摘自比特 - 维基百科
计算机中可以存储的最小单位是bit,内存分配的最小单位是Byte。
1 | 1Byte = 8bit ------>1个bit位,可以存一个二进制数 |
进制转换
不同进制的前导符:
- 十进制(Decimal):没有前导符,例如
42。 - 八进制(Octal):以
0开头,例如075表示八进制的75。 - 十六进制(Hexadecimal):以
0x或0X开头,例如0xA1表示十六进制的A1。 - 二进制(Binary):在C语言中,没有直接的前导符表示二进制,但可以使用前缀
0b或0B,例如0b1010表示二进制的1010。
1 | int decimal = 42; // 十进制 |
二进制表示法在C99标准中才被引入,不是所有的C编译器都支持它。因此,使用十六进制或八进制表示二进制数也是一种常见的做法。
| 基数 | 二进制 | 八进制 | 十进制 | 十六进制 |
|---|---|---|---|---|
| 数码 | 0、1 | 0-7 | 0-9 | 0-9A-F |
| 位权 | 从右至左:2^0 ,2^1 ,2^2···· | 从右至左:8^0 ,8^1 ,8^2··· | 从右至左:10^0 ,10^1 ,10^2··· | 从右至左:16^0 ,16^1 ,16^2··· |
任何进制,转十进制都是数码位权相加
i)十进制->二进制
辗转相除法
1 | 2|123 1 ^ 123=0111 1011 |
ii)二进制<->八进制
三位二进制数转换成一位八进制数;一位八进制数转换成三位二进制数
十进制转八进制115 ----> 163 用辗转相除法:
1 | 8|115 3 ^ 115=163(0) |
iii)二进制<->十六进制
四位二进制数转一位十六进制数;一位十六进制数转四位二进制
十进制转十六进制还是用辗转相除法
原码、反码和补码
-
原码(Sign-and-Magnitude):
- 最高位是符号位,0 表示正数,1 表示负数。
- 其余位表示数值的绝对值的二进制表示。
例如,
+5的原码是00000101,而-5的原码是10000101。原码的问题在于加法和减法需要不同的硬件电路,而且零有两种表示形式(正零和负零)。
-
反码:
- 与原码一样,最高位是符号位。
- 正数的反码和原码相同。
- 负数的反码是对其绝对值的原码按位取反。
例如,
+5的反码是00000101,而-5的反码是11111010。反码解决了零的两种表示形式的问题,但仍然存在加法和减法操作的问题。
-
补码:
- 补码是解决加法和减法问题的一种表示方式。
- 正数的补码和原码相同。
- 负数的补码是对其绝对值的原码按位取反,然后加 1。
例如,
+5的补码是00000101,而-5的补码是11111011。补码解决了零的两种表示形式的问题,而且加法和减法可以使用相同的硬件电路进行计算。
在计算机中,一般使用补码来表示带符号整数,因为补码有很多优点,包括简化电路设计、解决零的表示问题以及在加法和减法之间的一致性。
- 数据的二进制形式: 在计算机中,所有的数据都以二进制形式存储。这包括整数、小数、文本字符等。计算机中使用二进制的原因是因为数字电子电路最容易表示两种状态(通常是 0 和 1),这使得处理和存储信息更为高效。
- 二进制的补码形式: 对于带符号整数,计算机通常采用补码形式来表示。在补码中,正数的表示方式与无符号整数相同,而负数的表示方式是对其绝对值取补码(按位取反然后加 1)。补码的使用使得加法和减法可以通过相同的硬件电路实现,从而简化了计算机的设计。
- 计算机内部只有加法器: 计算机中的算术逻辑单元(ALU)通常包括加法器,而加法器是计算机内部进行数学运算的基本组成部分。通过使用补码表示,计算机可以使用相同的加法器执行加法和减法操作,这提高了计算机硬件的效率。
四、数据类型
数据类型的作用
- 能够让编译器识别该数据需要多的空间
- 方便取数据(防止一次取数据时取出数据的一半)
- 能够对字节进行准备的取数据运算(同样四个字节是按整形处理还是按小数处理)
数据类型的分类
在C语言中,数据类型可以分为基本数据类型(Primary Data Types)和派生数据类型(Derived Data Types)两大类。
i)基本数据类型
- 整数类型:
int:整数类型,通常使用32位(4字节)表示。short:短整数类型,通常使用16位(2字节)表示。long:长整数类型,通常使用32位或64位表示,具体取决于编译器和系统。long long:更长的整数类型,通常使用64位表示(C99标准引入)。
- 浮点数类型:
float:单精度浮点数,通常使用32位表示。double:双精度浮点数,通常使用64位表示。long double:扩展精度浮点数,具体位数取决于编译器和系统。
- 字符类型:
char:字符类型,通常使用8位表示。用于存储单个字符。
- 无符号整数类型:
unsigned int:无符号整数类型,不包含负数,范围为0到2^n-1(n是位数)。unsigned short:无符号短整数类型。unsigned long:无符号长整数类型。unsigned char:无符号字符类型。
- 布尔类型(在C99标准引入):
_Bool或bool:布尔类型,可以存储true或false。
ii)派生数据类型
- 数组类型:
- 用于存储相同类型的元素的集合。
- 指针类型:
- 存储其他变量地址的变量,用于实现间接访问。
- 结构体类型:
- 允许将不同类型的数据组合在一起,形成一个更大的数据结构。
- 联合类型:
- 允许在相同的内存位置存储不同类型的数据。
- 枚举类型:
- 定义一组命名的整数常量,使得代码更易读懂。
- 函数类型:
- 定义了函数的返回类型和参数类型。
| 数据类型 | 大小 | 占用字符格式符 | 取值范围 |
|---|---|---|---|
| 基本整数类型 | |||
int |
32位 | %d |
-2147483648 to 2147483647 |
short |
16位 | %hd |
-32768 to 32767 |
long |
32/64位 | %ld or %lld |
-2147483648 to 2147483647 (32位) -9223372036854775808 to 9223372036854775807 (64位) |
long long |
64位 | %lld |
-9223372036854775808 to 9223372036854775807 |
| 浮点数类型 | |||
float |
32位 | %f |
1.2E-38 to 3.4E+38(小数点后6/7位) |
double |
64位 | %lf |
2.3E-308 to 1.7E+308(小数点后15/16位) |
long double |
可变 | %Lf |
取决于编译器和系统 |
| 字符类型 | |||
char |
8位 | %c |
-128 to 127 (signed) 0 to 255 (unsigned) |
unsigned char |
8位 | %c |
0 to 255 |
| 无符号整数类型 | |||
unsigned int |
32位 | %u |
0 to 4294967295 |
unsigned short |
16位 | %hu |
0 to 65535 |
unsigned long |
32/64位 | %lu or %llu |
0 to 4294967295 (32位) 0 to 18446744073709551615 (64位) |
| 布尔类型 | |||
_Bool or bool |
1位 | %d (通常) |
0 (false) or 1 (true) |
| 派生数据类型 | |||
| 指针 | 取决于系统 | %p |
取决于系统 |
| 数组 | 取决于元素类型 | %s(字符串) |
- |
| 结构体 | 取决于成员类型 | - | - |
| 联合 | 取决于最大成员 | - | - |
什么是ASCII码
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是一种字符编码,用于将数字、字母、标点符号和其他字符与数字(整数)相对应。ASCII码是计算机系统中最基本的字符编码之一。
ASCII码使用7位二进制数(0到127)来表示128个字符,其中包括33个控制字符(用于控制设备和通信)和95个可显示字符(包括数字、字母、标点符号等)。后来的扩展版本将其扩展到8位,形成了扩展的ASCII码,提供了256个字符的编码空间。
查看ASCII码表手册:
1 | man ascii |
1 | Dec Char Dec Char Dec Char Dec Char |
要记住的字符的ASCII
0:48
a:97
A:65
\n:10
SPACE:32
字符型数据
字符型数据表示
单个字符,通常用char数据类型来声明。char类型占用一个字节的内存空间,可以存储一个字符,其取值范围通常是 -128 到 127 或者 0 到 255,取决于是有符号还是无符号字符。在ASCII字符集中,一个char可以表示一个标准ASCII字符。
字符常量是用单引号括起来的单个字符,例如:'A'、'5'、'$'。
字符数组是由字符组成的数组,每个元素都是一个char类型,最后以null字符 '\0' 结尾。
强制类型转换
在C语言中,强制类型转换是一种将一个数据类型的值转换为另一种数据类型的操作。这可以用于显式地告诉编译器执行类型转换,以确保代码的正确性。
注意:
大的数据类型向小的数据类型强转是不安全的,会发生数据的丢失
小的数据类型向大的数据类型转换是安全的, 不会发生数据丢失
整形和浮点型间的转换,会发生小数部分数据的丢失(也是不安全的)
有两种基本的强制类型转换方式:
i)隐式的强制类型转换
看不见过程,编译器自己完成的强转
1 |
|
ii)显式的强制类型转换
格式:
(目标数据类型)要强转的变量; ------>把括号外的变量强转成指定的数据类型
1 |
|
iii)有符号数和无符号数之间的强转
当有符号数和无符号数一起参与运算时,会被强转成无符号数
1 |
|
计算机中的数据存取
计算机中存储的都是数据的补码形式
存储数据时,看数据的值
取出数据时,看数据的类型
1 |
|
大小端存储
大端存储 地址低位存储数据高位,地址高位存储数据低位,用于大型网络
小端存储 地址低位存储数据低位,地址高位存储数据高位,常用于PC
五、常量和变量
变量(Variables)
-
定义变量: 在C语言中,变量必须在使用之前被声明,并且要指定其数据类型。例如:
1
2int age; // 声明一个整数型变量age
double salary; // 声明一个双精度浮点型变量salary -
初始化变量: 变量可以在声明的同时进行初始化,也可以在后续的代码中进行赋值。例如:
1
int count = 0; // 初始化整数型变量count为0
-
变量命名规则: 变量名由字母、数字和下划线组成,但必须以字母或下划线开头。不能和C语言的32个关键字重复,变量名对大小写敏感。
1
2int myVariable;
double my_salary; -
作用域: 变量有其作用域,即其可见的范围。一般而言,变量的作用域在其声明的代码块内有效。
-
存储类型:(6种): ----->前期学习的阶段,都用不到存储类型
1
2
3
4
5
6auto:自动
static:静态
const:常属性
extern:引入外部其他文件中的变量
register:寄存器类型(把变量定义在寄存器)
volatile:防止代码优化(每次从内存中取最准确的值) -
命名规范:
1
2
3
4
5
6变量名是一个标识符要遵循标识符的命名规范
1、由数字、字母和下划线构成
2、不能以数字开头
3、严格区分大小写
4、不能和C语言的32个关键字重复(不需要记关键字,关键字在文件中会高亮)
5、尽量见名知义 -
示例:
1
2
3
4
5
6
7
int main() {
int x = 5; // 声明并初始化变量x
printf("The value of x is %d\n", x); // 打印变量x的值
return 0;
}
常量(Constants)
-
字面常量: 字面常量是固定的值,不可修改。例如:
1
printf("Hello, World!\n"); // "Hello, World!" 是一个字符串字面常量
-
符号常量(宏常量): 使用
#define关键字可以定义符号常量,一般用大写字母表示。1
-
const关键字: 使用
const关键字可以创建常量变量,其值一旦初始化就不能再修改。1
const int MAX_VALUE = 100;
-
枚举常量: 使用
enum关键字可以创建一组命名的整数常量。1
enum Days {SUNDAY, MONDAY, TUESDAY, WEDNESDAY, THURSDAY, FRIDAY, SATURDAY};
-
示例:
1
2
3
4
5
6
7
8
9
10include <stdio.h>
int main() {
const int MAX_COUNT = 100; // 声明常量变量MAX_COUNT
printf("The value of PI is %f\n", PI);
printf("The maximum count is %d\n", MAX_COUNT);
return 0;
}
六、标准输入和输出函数
printf
1 | 函数原型: |
scanf
1 | 函数原型: |
scanf在获取字符类型数据时吸收垃圾字符
字符类型的数据属于非数值型数据,存储的是ASCII的形式
scanf在获取数据时,以空格、tab键和回车作为数据的分隔
但是空格、tab键和回车同时又是一个字符,可以被%c格式符获取
i)利用scanf严格控制格式的特点
1 |
|
getchar
1 | 函数原型: |
putchar
1 | 函数原型: |
七、运算符
算术运算符
+:加法-:减法*:乘法/:除法%:取余(取模)
1 | int a = 10, b = 3; |
关系运算符
关系运算符用于比较两个值之间的关系,返回一个布尔值(0表示False,非0表示True)
==:等于!=:不等于<:小于>:大于<=:小于等于>=:大于等于
逻辑运算符
&&:逻辑与(AND)当且仅当两个条件都为真时,整个表达式的值为真。||:逻辑或(OR)只要有一个条件为真,整个表达式的值就为真。!:逻辑非(NOT)用于取反,如果条件为真,则取反后为假;如果条件为假,则取反后为真。
赋值运算符
=:赋值+=:加法赋值-=:减法赋值*=:乘法赋值/=:除法赋值%=:取余赋值^=:按位异或赋值运算符
逗号运算符
逗号运算符(,)在C语言中是一个二元运算符,它用于在表达式中连接两个表达式,从左到右依次执行这两个表达式,并返回最右边表达式的值。
逗号运算符的语法如下:
1 | expr1, expr2 |
在执行时,先计算 expr1,然后计算 expr2,最后返回 expr2 的值。逗号运算符的优先级是最低的,因此它会在大多数其他运算符之后执行。
逗号运算符的一些常见用法包括:
-
在
for循环中初始化和更新多个变量:1
2
3for (int i = 0, j = 10; i < 5; ++i, --j) {
// 循环体
} -
在函数调用时,多个参数表达式:
1
int result = myFunction(arg1, arg2, arg3);
-
在语句块中,执行多个语句:
1
2
3if (condition) {
printf("Condition is true. "), printf("This is another statement.\n");
}
逗号运算符的使用需要谨慎,因为它可能会使代码变得难以理解。在一般情况下,尽量避免在表达式中过多地使用逗号运算符,以保持代码的可读性。
自增和自减运算符
++:自增--:自减
-
前缀形式: 先执行自增或自减操作,然后使用新的值。
1
2++x; // 自增,x的值会先加1,然后使用新的值
--y; // 自减,y的值会先减1,然后使用新的值 -
后缀形式: 使用变量的当前值,然后再执行自增或自减操作。
1
2x++; // 自增,先使用x的当前值,然后x的值加1
y--; // 自减,先使用y的当前值,然后y的值减1
位运算符
位运算符用于在二进制位级别上操作整数的各个位。在C语言中,有几个常见的位运算符:
-
按位与(&):对两个数的每一位执行与操作,如果两个相应的位都是1,则结果位为1,否则为0。
1
result = a & b;
-
按位或(|):对两个数的每一位执行或操作,如果两个相应的位中至少有一个是1,则结果位为1,否则为0。
1
result = a | b;
-
按位异或(^):对两个数的每一位执行异或操作,如果两个相应的位相异,则结果位为1,否则为0。
1
result = a ^ b;
-
按位取反(~):对数的每一位执行取反操作,即将0变为1,将1变为0。
1
result = ~a;
-
左移(<<):将一个数的所有位向左移动指定的位数,右侧空出的位用0填充。
1
result = a << n;
-
右移(>>):将一个数的所有位向右移动指定的位数,左侧空出的位使用原来的最高位填充(有符号数用符号位填充,无符号数用0填充)。
1
result = a >> n;
条件运算符
唯一一个三元运算符
表达式中使用的简洁的条件语句。它使用以下语法:
1 | condition ? expression_if_true : expression_if_false; |
其中,condition 是一个条件表达式,如果它的值为真(非零),则整个表达式的值为 expression_if_true,否则为 expression_if_false。
下面是一个简单的例子:
1 |
|
在这个例子中,如果 a > b 为真,max 将被赋值为 a,否则被赋值为 b。在实际应用中,条件运算符通常用于简单的条件判断,以便在一行代码中完成简单的赋值操作。
sizeof运算符
sizeof 是C语言中的一个运算符,用于获取数据类型或变量的大小(以字节为单位)。sizeof 运算符返回一个 size_t 类型的值,表示操作数占用的存储空间大小。
sizeof 运算符的基本语法如下:
1 | sizeof (type) |
其中,type 是数据类型,expression 是一个表达式、变量或数组。
一些示例:
-
获取数据类型的大小:
1
2size_t intSize = sizeof(int);
size_t doubleSize = sizeof(double); -
获取变量的大小:
1
2int myInt;
size_t intVariableSize = sizeof(myInt); -
获取数组的大小:
1
2cCopy codeint myArray[10];
size_t arraySize = sizeof(myArray);这将返回整个数组占用的存储空间大小。
-
获取结构体的大小:
1
2
3
4
5
6struct Point {
int x;
int y;
};
size_t structSize = sizeof(struct Point);这将返回结构体
Point占用的存储空间大小。
sizeof 运算符对于编写可移植的代码很有用,因为它可以确保在不同系统上,相同类型的数据都使用正确的字节大小。在进行内存分配、复制和其他涉及内存大小的操作时,sizeof 运算符是一个重要的工具。
运算符优先级
| 优先级 | 运算符 | 描述 |
|---|---|---|
| 1 | () | 括号 |
| 2 | ++ – | 后缀自增、后缀自减 |
| + - | 一元正号、一元负号 | |
| ! ~ | 逻辑非、按位取反 | |
| ++ – | 前缀自增、前缀自减 | |
| (类型) | 强制类型转换 | |
| sizeof | 计算对象大小 | |
| 3 | * / % | 乘法、除法、取余 |
| 4 | + - | 加法、减法 |
| 5 | << >> | 左移、右移 |
| 6 | < <= | 小于、小于等于 |
| > >= | 大于、大于等于 | |
| 7 | == != | 等于、不等于 |
| 8 | & | 按位与 |
| 9 | ^ | 按位异或 |
| 10 | | | 按位或 |
| 11 | && | 逻辑与 |
| 12 | || | 逻辑或 |
| 13 | ?: | 条件运算符 |
| 14 | = += -= *= | 赋值、加法赋值、减法赋值、乘法赋值 |
| /= %= &= | 除法赋值、取余赋值、按位与赋值 | |
| ^= | = <<= >>= | |
| 15 | , | 逗号 |
八、条件语句
if语句
if 语句允许程序根据条件执行不同的代码块。基本语法结构如下:
1 | if (条件) { |
else 部分是可选的,可以根据需要省略。如果只有单一的条件,可以省略 else 部分。
switch语句
1 | switch (表达式) { |
break 语句用于退出 switch 语句,防止继续执行其他 case。default 语句是可选的,用于处理表达式值不匹配任何 case 的情况。
“case穿透”(case fall-through)是一种现象,指的是当一个case标签匹配后,程序会执行该case标签下的代码,并继续执行后续的case标签而不进行跳出。这是switch语句的一个特性,而非错误。
九、循环语句
C 语言提供了三种主要的循环结构,分别是 for 循环、while 循环和 do-while 循环。这些循环结构允许程序根据某个条件重复执行一段代码块。
for循环->计数循环
1 | for (初始化表达式; 循环条件; 更新表达式) { |
- 初始化表达式(Initialization Expression): 在循环开始前执行,通常用于初始化循环变量。这个表达式只在循环开始时执行一次。
- 循环条件(Loop Condition): 是一个布尔表达式,当为真(true)时,执行循环体。当为假(false)时,退出循环。
- 更新表达式(Update Expression): 在每次循环迭代之后执行,通常用于更新循环变量。这个表达式在每次循环迭代后执行,然后重新检查循环条件。
while循环->条件循环
1 | while (循环条件) { |
循环条件(Loop Condition): 是一个布尔表达式,当为真(true)时,执行循环体。当为假(false)时,退出循环。在每次循环迭代开始前,都会检查循环条件。
do-while 循环
1 | do { |
- 循环体: 至少执行一次的代码块。
- 循环条件(Loop Condition): 是一个布尔表达式,当为真(true)时,继续执行循环体。当为假(false)时,退出循环。
十、数组
一维字符数组
定义格式:
1 | 存储类型 char 数组名[常量表达式] |
1 | char a; // 存储一个单字符 |
1 | char str[10]; // 存储10个单字符 |
字符串:表示0个或多个字符组成的整体(标识是\0,一般使用 "",汉字均属于字符串)
"a" ×'a' "" "+-" "你好"
字符数组是容器,字符串是值,字符数组大于字符串
字符数组的初始化
1 | 1.单字符定义及初始化 |
字符串长度和字符数组长度
字符串长度:使用strlen函数,实际字符的个数,遇到\0结束,不计算\0
字符数组长度:使用关键字sizeof,计算\0
十一、函数
十二、指针
指针是C语言的灵魂!
指针:就是地址,每个字节的编号,称为指针
指针变量:存储地址/指针的容器
优点:指针变量可以指向计算机任意一块内存,可以是程序更简洁,加快运行速度
指针变量的定义
格式:存储类型 数据类型 *指针变量名
1 | int* p; |
解析:
1.存储类型:auto\static\extern\register\const\volatile
2.数据类型:基类型 空类型 指针类型 构造类型
3.*:指针的说明符,表明这是一个指针
4.指针变量名:满足命名规范
1 | int *p; //p的数据类型时int* int表示指针指向地址对应值的数据类型,偏移量 |
指针字节大小
注意:指针的大小和操作系统有关,和数据类型无关
64位操作系统,占8字节
32位操作系统,占4字节
指针变量的定义和初始化
1 | 1.指针的类型和地址的类型保持一致 |
解引用和取地址
*:乘法、说明符,取值(解引用)
&:取地址,逻辑与、按位与
注意:在使用时,带 * 表示值,不带*表示地址
*和&属于逆运算
总结:
地址:p---->&a—>&*p---->&(*p)
值 :*p–>a---->*&a—>*(&a)
指针的运算
i) 算数运算
1 | int a=100;int *p=&a; |
int a=100;int *p=&a;
| 符号 | 说明 |
|---|---|
+: |
|
| p+n | 向高地址方向偏移n倍的数据类型字节大小 |
| *p+n | 先取p指向地址对应的值,在对值加n |
| *(p+n) | 向高地址方向偏移n倍的数据类型字节大小,在取值 |
| &p+n | 向高地址方向偏移n倍的指针字节大小 |
| &a+n | 向高地址方向偏移n倍的数据类型字节大小 |
-: |
|
| p-n | 向低地址方向偏移n倍的数据类型字节大小 |
| *p-n | 先取p指向地址对应的值,在对值减n |
| *(p-n) | 向低地址方向偏移n倍的数据类型字节大小,在取值 |
| &p-n | 向低地址方向偏移n倍的指针字节大小 |
| &a-n | 向低地址方向偏移n倍的数据类型字节大小 |
++ --: |
|
| p++ | 后缀运算,先使用p,向高地址方向偏移1个数据类型字节大小 |
| ++p | 前缀运算,先向高地址防线偏移1个数据类型字节大小,在使用 |
*()++: |
|
| (*p)++ | 先取值,后缀运算,先使用,后对值自增 |
| ++*p | 先取值,前缀运算。先对值自增,后使用 |
| *p++ | 先p++,但是后缀运算,先取值,后向高地址方向偏移1个数据类型字节大小 |
| *(p++) | 先p++,但是后缀运算,先取值,后向高地址方向偏移1个数据类型字节大小 |
| ++(*p) | 先取值,前缀运算,先对值自增,后使用 |
| *++p | 先++p,前缀运算,先向高地址方向偏移1个数据类型字节大小,在取值 |
ii)赋值运算
1 | = += -= |
| = | int a=10;int *p=&a | 1,不可以把指针赋值为值 int *p=1002,等号的左边是变量,右边可以是常量,变量3,建议等号的左右两端指针的类型和地址的类型保持一致 |
|---|---|---|
| += | p+=1 -->p=p+1 | 向高地址方向偏移1个数据类型字节大小 |
| -= | p-=1—>p=p-1 | 向低地址方向偏移1个数据类型字节大小 |
iii)关系运算
1 | > >= < <= == != |
注意:关系运算,多适用于地址连续的情况,eg:数组
| > | p>q | 如果p地址大于q的地址成立1,不成立为0 |
|---|---|---|
| >= | p>=q | 如果p地址大于等于q的地址成立1,不成立为0 |
| < | p<q | 如果p地址小于q的地址成立1,不成立为0 |
| <= | p<=q | 如果p地址小于等于q的地址成立1,不成立为0 |
| == | p==q | 如果p地址等于q的地址成立1,不成立为0 |
| != | p!+q | 如果p地址不等与q的地址成立1,不成立为0 |
指针和一维数组
1 | int arr[5]={11,22,33,44,55}; |
数组名表示数组的首地址,也就是第一个元素的地址 arr--->&arr[0]
i)数组和指针地址偏移
1 | &arr[0] &arr[0]+1 |
ii) 数组和地址之间引用的等价关系
1 | int main(int argc, const char *argv[]) |
地址:&arr[i]-->&arr[0]+i-->arr+i --->&p[i]-->&p[0]+i--->p+i--->p++
值:arr[i]-->*(&arr[0]+i)-->*(arr+i) ---> p[i]-->*(&p[0]+i)--->*(p+i)--->*p++
iii) 指针和数组结合练习
1 | 1.定义有参无返函数实现输入, |