〇、数据和数据结构
1>认识数据
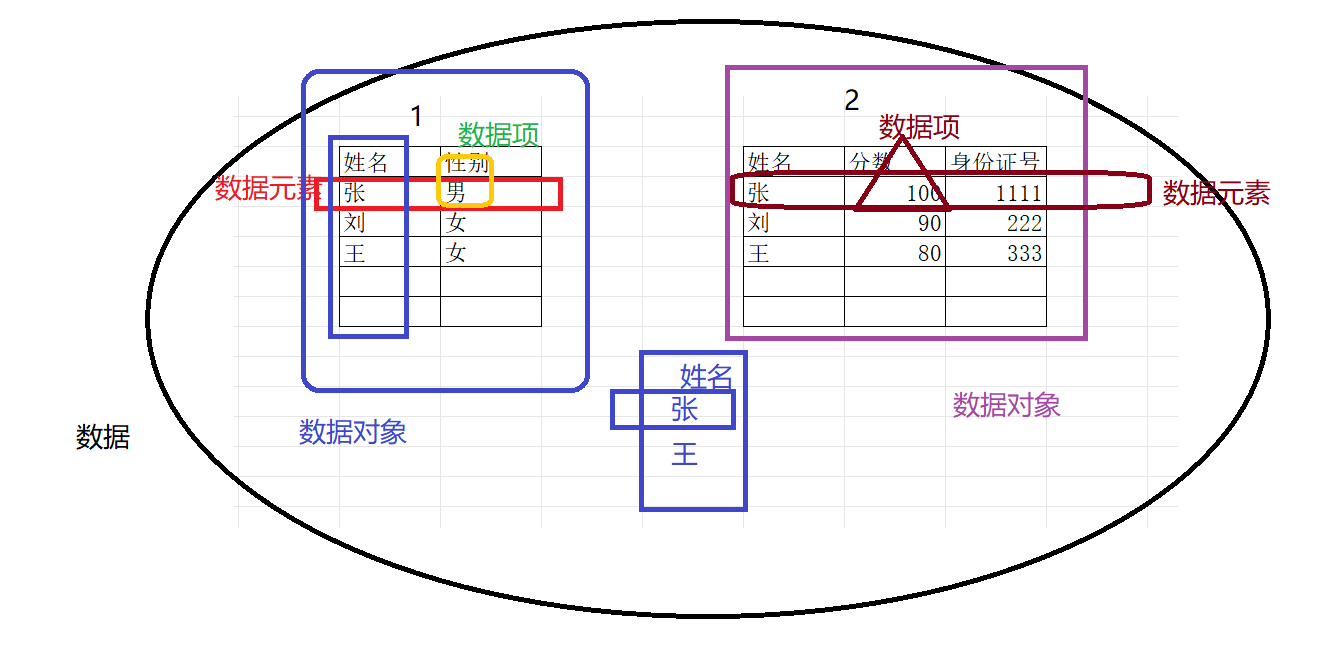
数据 :能被计算机识别,存储,处理的符号
数据类型(整数,小数,字符,字符串,汉字)
非数据类型(声音,图片,视频,文件,app)
数据元素 :由数据项组成,数据的基本单位
数据项 :值数据的最小单位
数据对象 :类型相同的数据元素组成
数据 > 数据对象> 数据元素> 数据项
2> 数据结构
数据结构:存储多个类型相同的数据元素之间一种或多种关系的集合
D_S=(D,R)
i> 逻辑结构
数据元素之间的一种或多种关系
1.集合结构 :数据元素之间没有关系(地铁上的人)
2.线性结构 :数据元素之间存在一对一的逻辑关系(数组,地铁的座位)头节点无直接前驱,尾节点无直接后继,中间节点存储在唯一的前驱唯一的后继
3.树形结构 :数据元素之间存在一对多的逻辑关系(族谱,公司架构)头结点无直接前驱,尾节点无直接后继,中间节点存在唯一的直接前驱,多个后继
4.图形结构 :数据元素之间存在多对多的逻辑关系(地图)
ii>存储结构
逻辑结构在计算机的存储形式
顺序存储 :使用一段连续的存储空间实现存储(数组)
链式存储 :使用任意一段空间实现存储(银行取现)
散列存储 :称为哈希存储,关键字通过哈希函数映射在内存地址的一种存储形式(词典)
实现查找
索引存储 :使用索引表和数据文件共同实现的查找方式
实现查找
3> 时间复杂度
时间复杂度:程序的执行次数
T(n)=O(f(n))
T: time时间
T(n):时间复杂度
O:大O阶 渐进符
n:问题的规模
f(n): 问题规模的函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 注意:只保留最高阶 f(n)=3 *n^4 +4 *n^2 +5 *n+100 ---->3 *n^4 ---->n^4 T(n)=O(f(n))--->O(n^4 ) int t=a; 1 a=b; 1 b=t; 1 f(n)=3 --->3 *n^0 ---->n^0 --->1 T(n)=O(1 ) for (int i=1 ;i<=n;i++) n+1 { puts ("hello" ); n } f(n)=2 *n+1 --->2 *n--->n T(n)=O(n) for (int i=1 ;i<=n;i++) n+1 { for (int j=1 ;j<=n;j++) (n+1 )*n { puts ("hello" ); n*n } } f(n)=2 *n^2 +2 *n+1 ---->2 *n^2 ---->n^2 T(n)=O(n^2 ) for (int i=1 ;i<=n;i++) { for (int j=1 ;j<=n;j++) { for (int k=1 ;k<=n;k++) { puts ("hello" ); } } } int i=1 ; 1 while (i<n) log2n +1 { i*=2 ; log2n } 2 ^次数=n 次数=log2 n f(n)=2 *log2n+2 ---->log2n
一、线性表
线性表是存储类型相同、个数有限的一个集合(属相)
线性表:线性结构
线性结构是一种元素之间存在一对一的关系,即每个元素都有唯一的直接前驱和直接后继。线性表就是一种典型的线性结构。
存储结构:顺序存储,链式存储
在顺序存储结构中,线性表的元素在内存中占用一段连续的存储空间。顺序表通常使用数组来实现,通过数组的下标来访问元素。
在链式存储结构中,线性表的元素在内存中可以是不连续的,通过指针来连接各个元素。链表是一种常见的链式存储结构,包括单链表、双链表等。
线性表:顺序表,链表,数组,栈,队列,字符串
二、顺序表
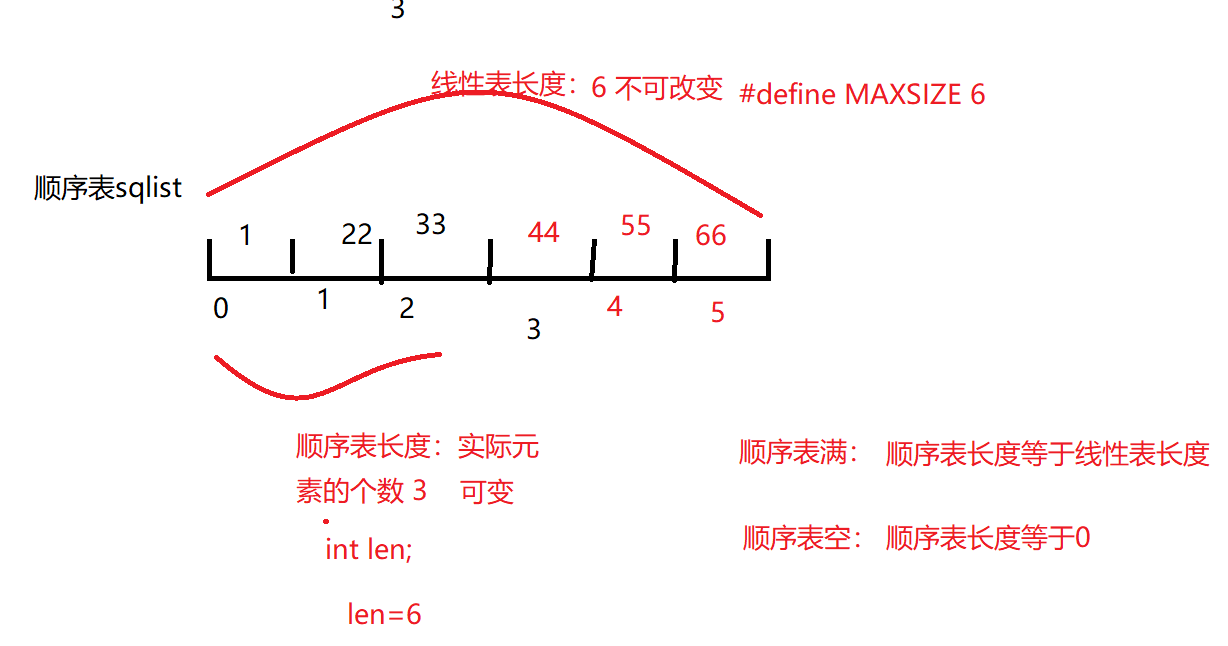
1> 顺序表概念
顺序表:线性表的顺序存储就是顺序表
顺序表的逻辑结构:线性结构(一对一)
顺序表的存储结构:顺序存储(地址连续)
特点:逻辑相邻物理也相邻
顺序表是借助于数组实现的,但是不等价数组
顺序表下表从0开始
顺序表长度len:实际元素的个数
线性表长度/数据长度MAXSIZE:不可以改变,表示顺序表的最大空间
顺序表满:len==MAXSIZE
顺序表空:len==0
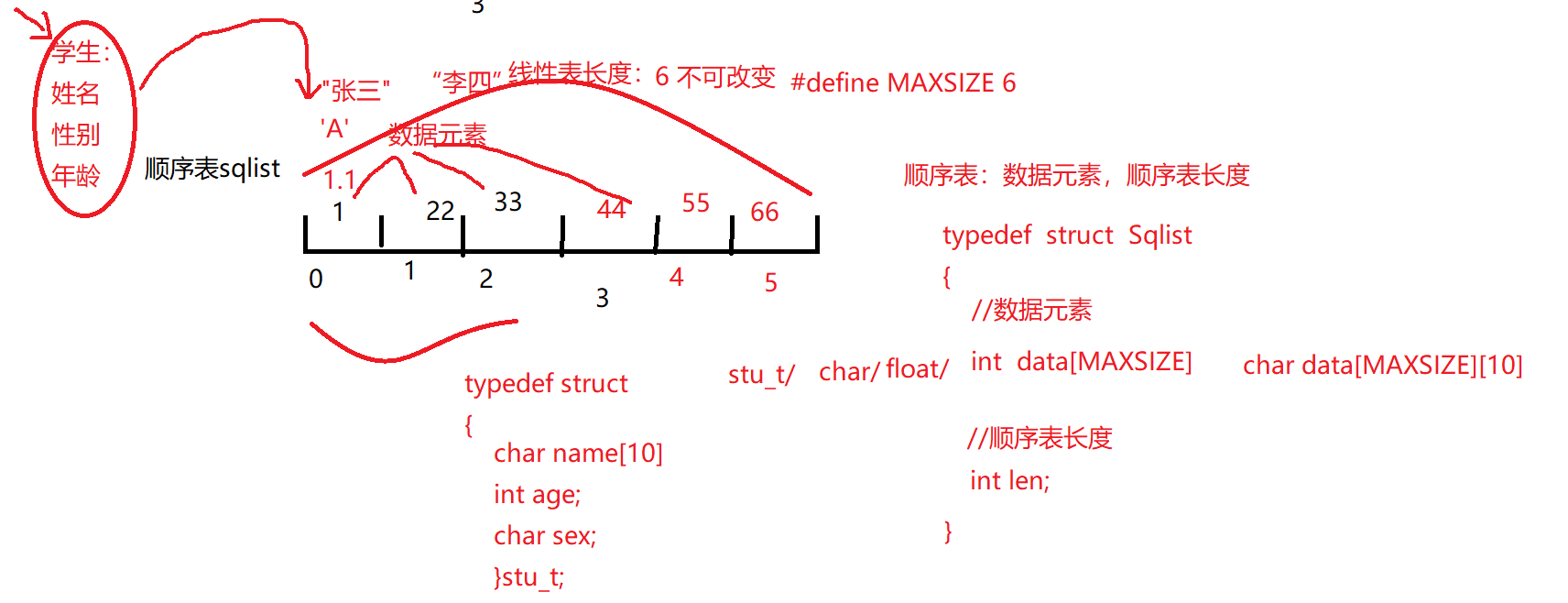
顺序表的定义
顺序表:数据元素,顺序表长度
2> 顺序表的操作
1) 顺序表堆区创建
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 sqlist* create_list () { sqlist *list =(sqlist*)malloc (sizeof (sqlist)); if (NULL ==list ) return NULL ; memset (list ->data,0 ,sizeof (list ->data)); list ->len=0 ; S return list ; }
1) 顺序表尾插+判满
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 int full (sqlist*list ) { return list ->len==MAXSIZE?FALSE:SUCCESS; } int insert_rear (sqlist *list ,datatype element) { if (NULL ==list || full(list )) { return FALSE; } list ->data[list ->len]=element; list ->len++; return SUCCESS; }
3) 顺序表尾删
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 int delete_rear (sqlist*list ) { if (NULL ==list || empty(list )) return FALSE; list ->len--; return SUCCESS; }
4) 顺序表遍历+判空
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 int empty (sqlist *list ) { return list ->len==0 ?FALSE:SUCCESS; } int Output (sqlist *list ) { if ( NULL ==list || empty(list )) return FALSE; for (int i=0 ;i<list ->len;i++){ printf ("%d\t" ,list ->data[i]); } puts ("" ); return SUCCESS; }
5) 顺序表按下标插入
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 int insert_index (sqlist* list ,int index,datatype element) { if (NULL ==list || isFull(list ) || index<0 || index>list ->len) return FALSE; for (int i = list ->len-1 ; i >= index; i--) { list ->data[i+1 ]=list ->data[i]; } list ->data[index]=element; list ->len++; return SUCCESS; }
6) 顺序表按下标删除
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 int delete_index (sqlist* list ,int index) { if (NULL ==list || isEmpty(list ) || index<0 || index>=list ->len) return FALSE; for (int i=index+1 ;i< list ->len ;i++) { list ->data[i-1 ]=list ->data[i]; } list ->len--; return SUCCESS; }
7) 顺序表按下表修改
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 int update_index (sqlist*list ,int index,datatype element) { if (NULL ==list || empty(list )|| index<0 || index>=list ->len) return FALSE; list ->data[index]=element; return SUCCESS; }
8) 顺序表按下表查找
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 void search_index (sqlist*list ,int index) { if (NULL ==list || empty(list )|| index<0 || index>=list ->len) return ; printf ("search by index element is %d\n" ,list ->data[index]); }
9) 按元素查找
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 int search_key (sqlist* list ,datatype key) { int in=-1 ; if (NULL ==list || isEmpty(list )) return FALSE; for (int i = 0 ; i < list ->len; i++) { if (list ->data[i]==key){ in=i; break ; } } if (in==-1 ){ return FALSE; }else { return in; } }
10) 顺序表按元素删除(如果存在重复则只能删除第一个)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 int delete_key (sqlist* list ,datatype key) { int in=search_key(list ,key); if (in==FALSE) return FALSE; return delete_index(list ,in); }
11) 顺序表按元素修改
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 int change_key (sqlist* list ,datatype key,datatype new) { int in=search_key(list ,key); if (in==FALSE) return FALSE; update_index(list ,in,new); return SUCCESS; }
12) 顺序表去重
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 int deduplicate (sqlist* list ) { for (int i = 0 ; i < list ->len-1 ; i++) { for (int j = i+1 ; j < list ->len-i; j++) { if (list ->data[i]==list ->data[j]){ delete_index(list ,j); j--; } } } }
13) 顺序表排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 int sort (sqlist* list ) { if (NULL ==list || isEmpty(list )) return FALSE; for (int i = 0 ; i < list ->len-1 ; i++) { for (int j = 0 ; j < list ->len-i-1 ; j++) { if (list ->data[j] > list ->data[j+1 ]){ datatype temp=list ->data[j]; list ->data[j]=list ->data[j+1 ]; list ->data[j+1 ]=temp; } } } return SUCCESS; }
14) 顺序表释放
1 2 3 4 5 6 7 8 9 10 11 12 13 14 sqlist* my_free (sqlist* list ) { if (NULL ==list || isEmpty(list )) return NULL ; free (list ); list =NULL ; return list ; }
三、链表
链表:线性表的链式存储,称为链表
逻辑结构:线性结构(一对一)
存储结构:链式存储(使用任意一段存储空间实现的存储形式)
链表特点:逻辑相邻,物理不一定相邻
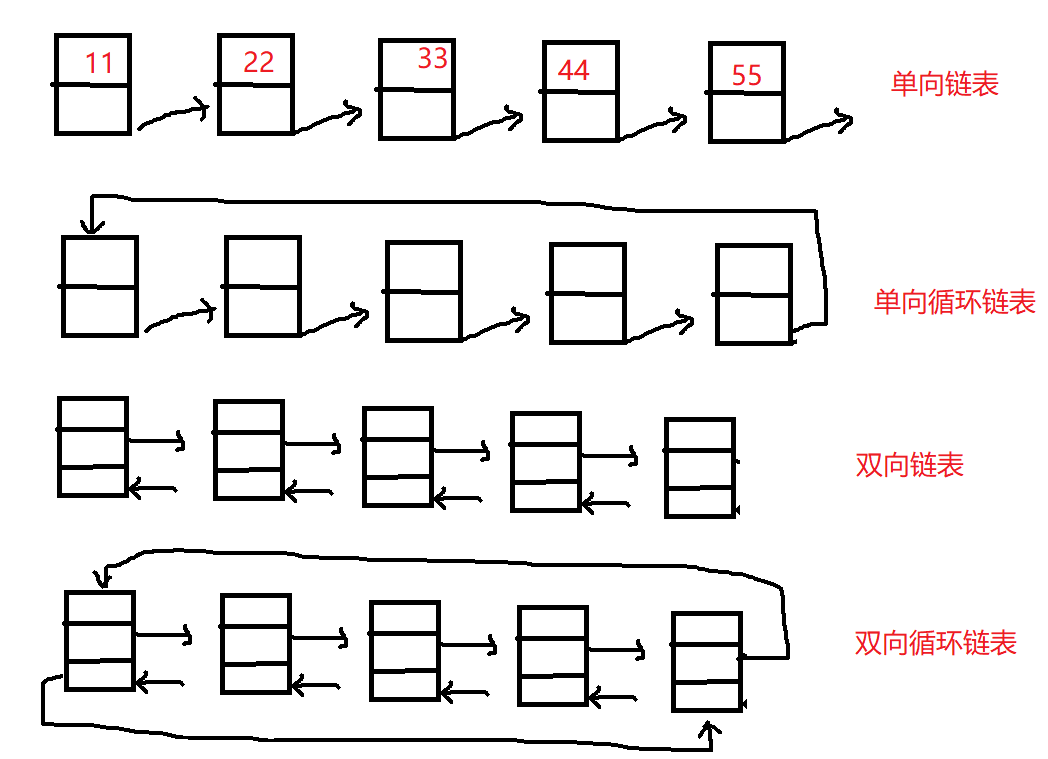
链表分类:单向链表、单向循环链表、双向链表、双向循环链表
引入目的:顺序表的插入和删除时间复杂度是O(n),需要移动大量元素,效率低,
并且顺序表存在满的情况,引出链表,插入和删除不需要移动元素。
1> 单链表的概念
1.单向链表:链表只可以单向遍历
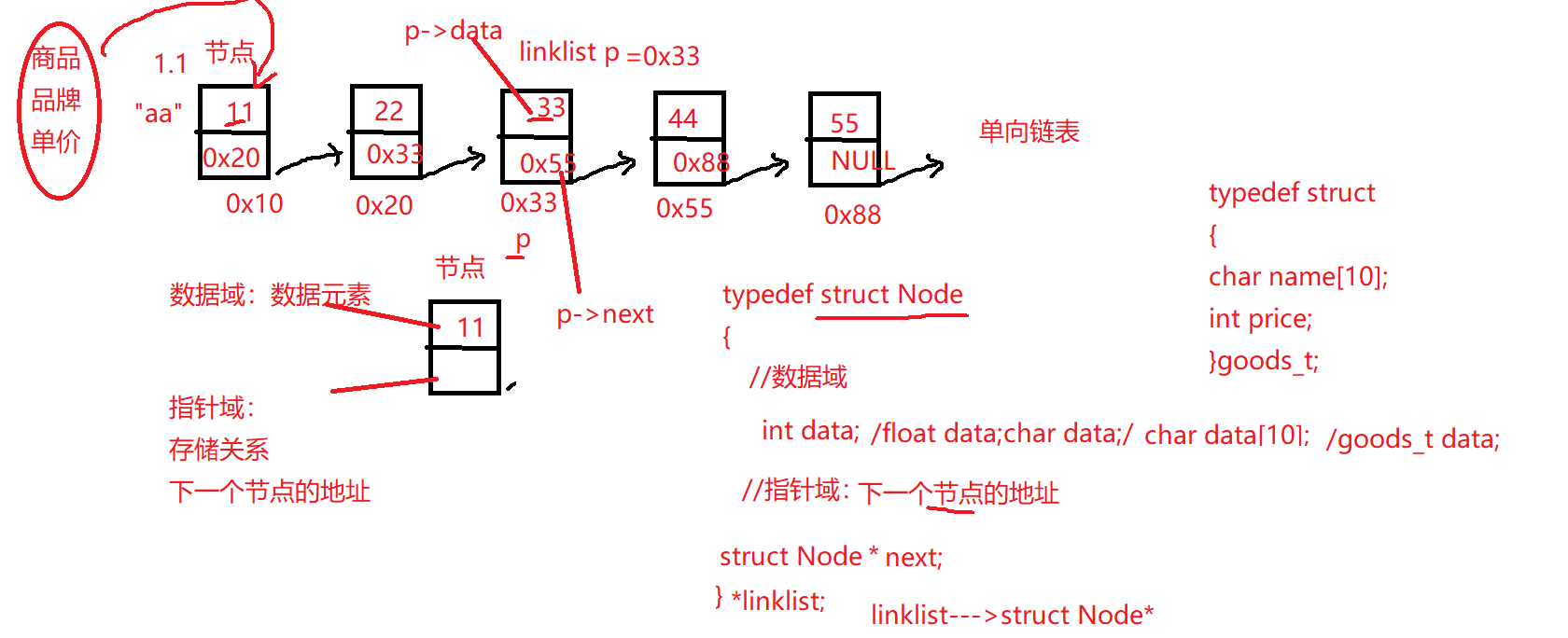
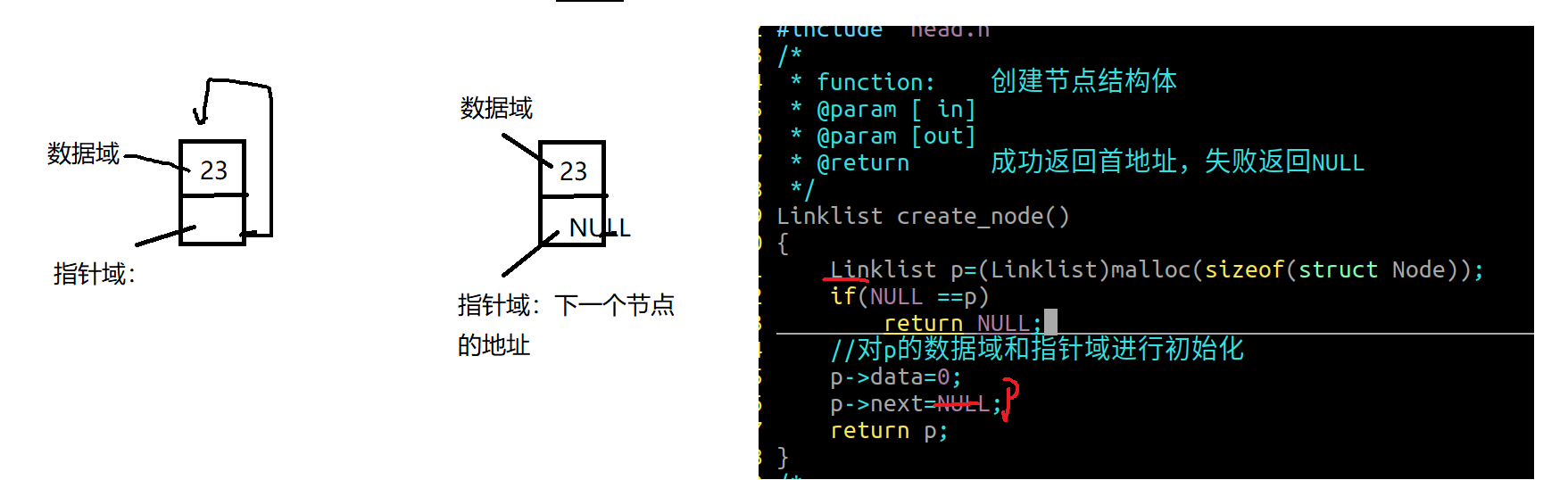
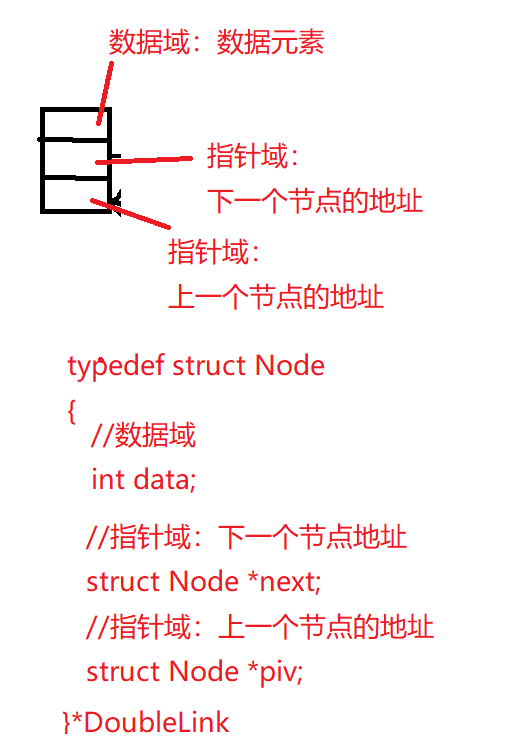
2.认识节点:
单向链表的节点:数据域、指针域
数据域:存储数据元素
指针域:节点之间的关系(下一个节点的地址)
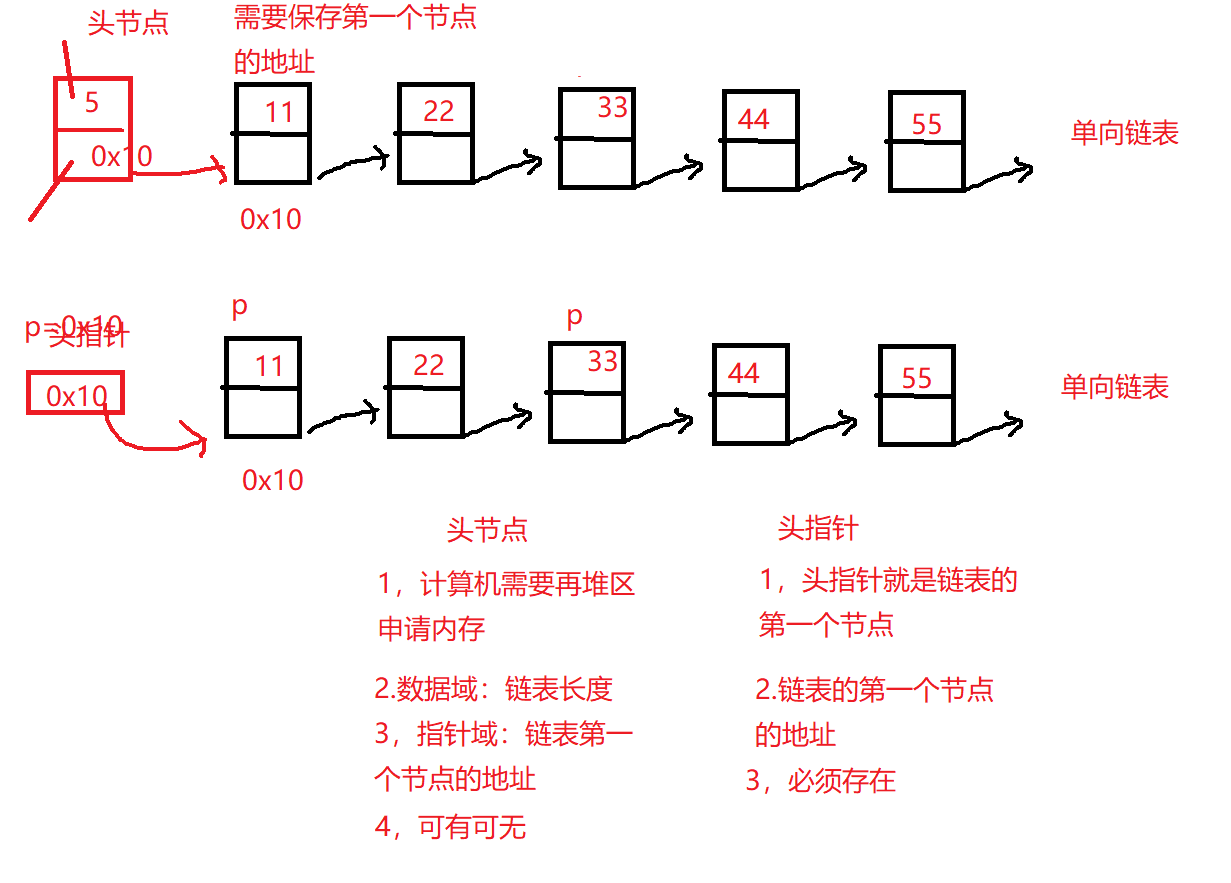
3.头节点和头指针
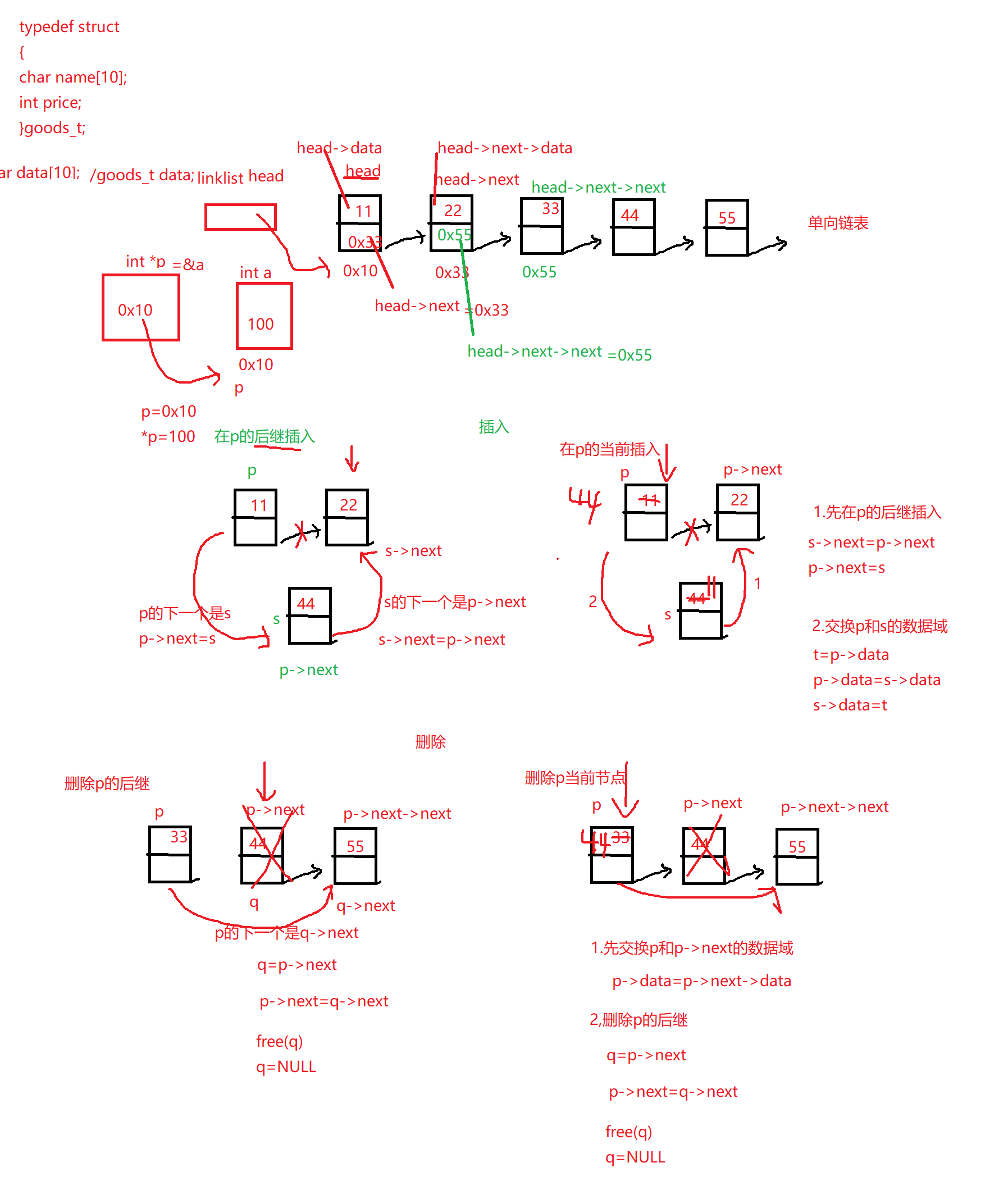
4.插入和删除
2> 单链表的操作
1.单向链表节点创建
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 typedef int datatype;typedef struct Node { datatype data; struct Node * next ; }*linklist; linklist creat_node () { linklist p=(linklist)malloc (sizeof (struct Node)); if (NULL == p) return NULL ; p->data=0 ; p->next=NULL ; return p; }
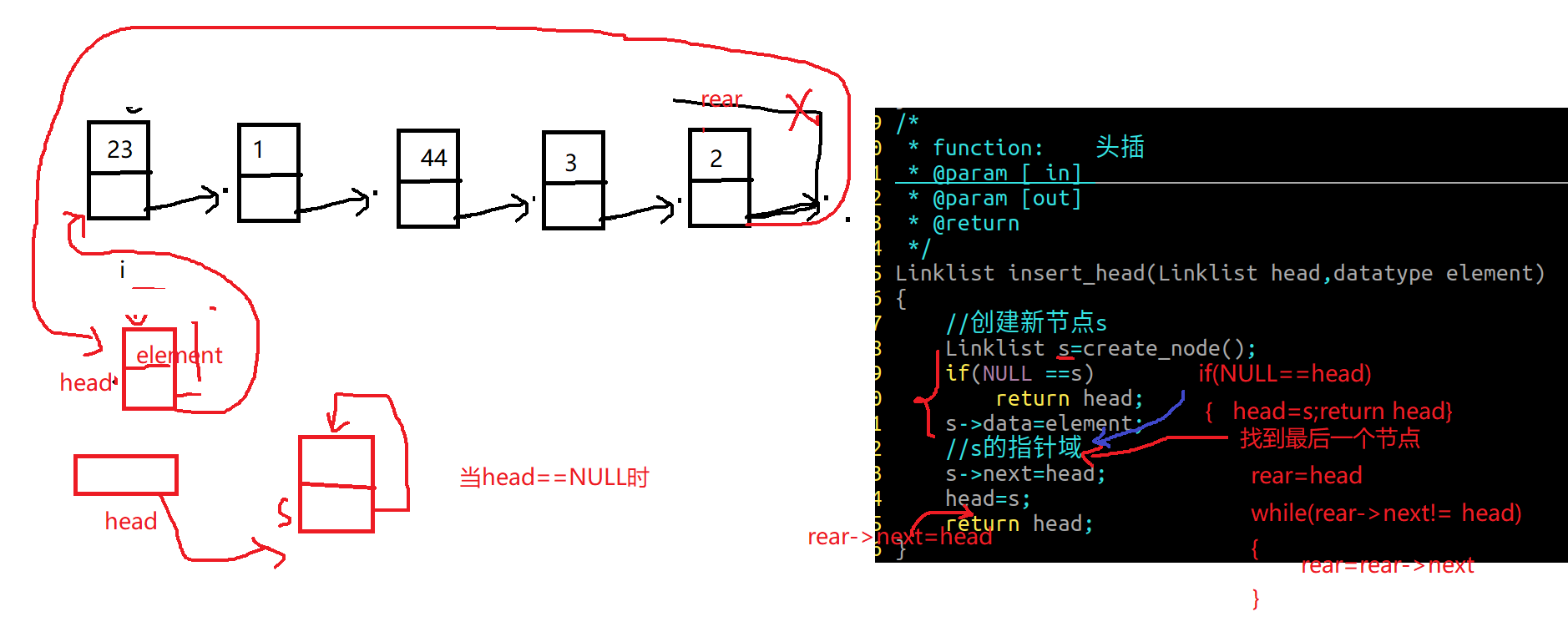
2.单向链表头插
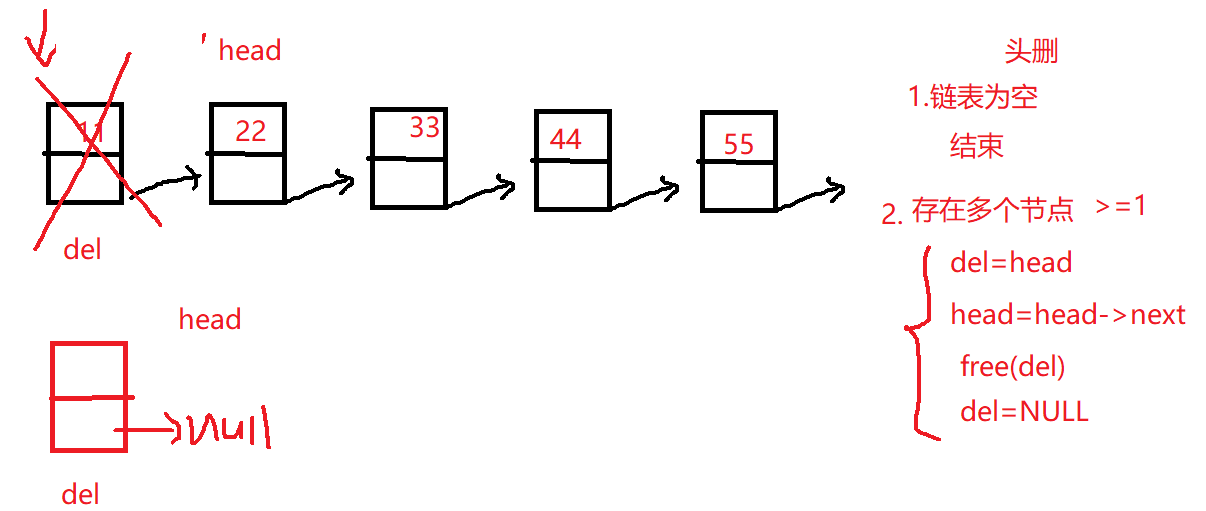
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 linklist delete_head (linklist list ) { if (NULL ==list ) return list ; linklist del=list ; list =list ->next; free (del); del=NULL ; return list ; }
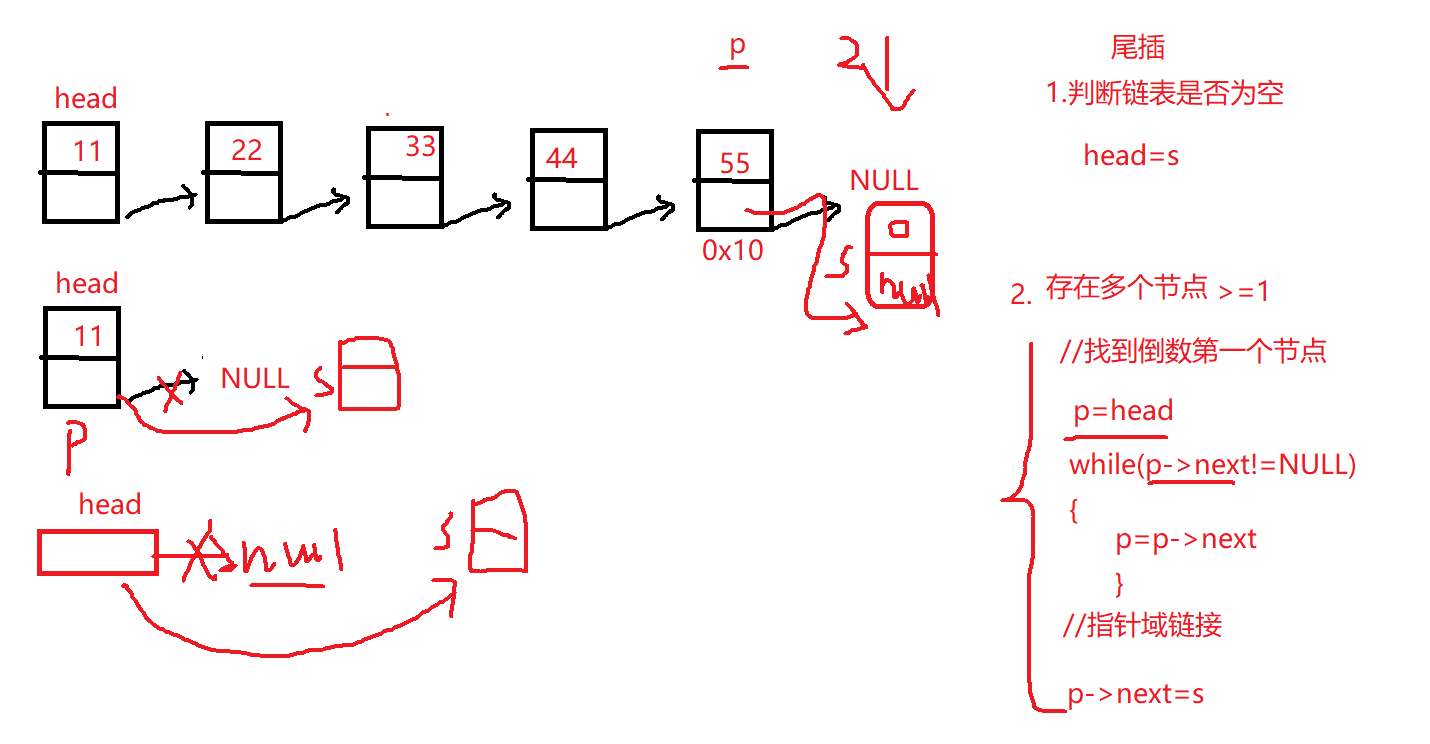
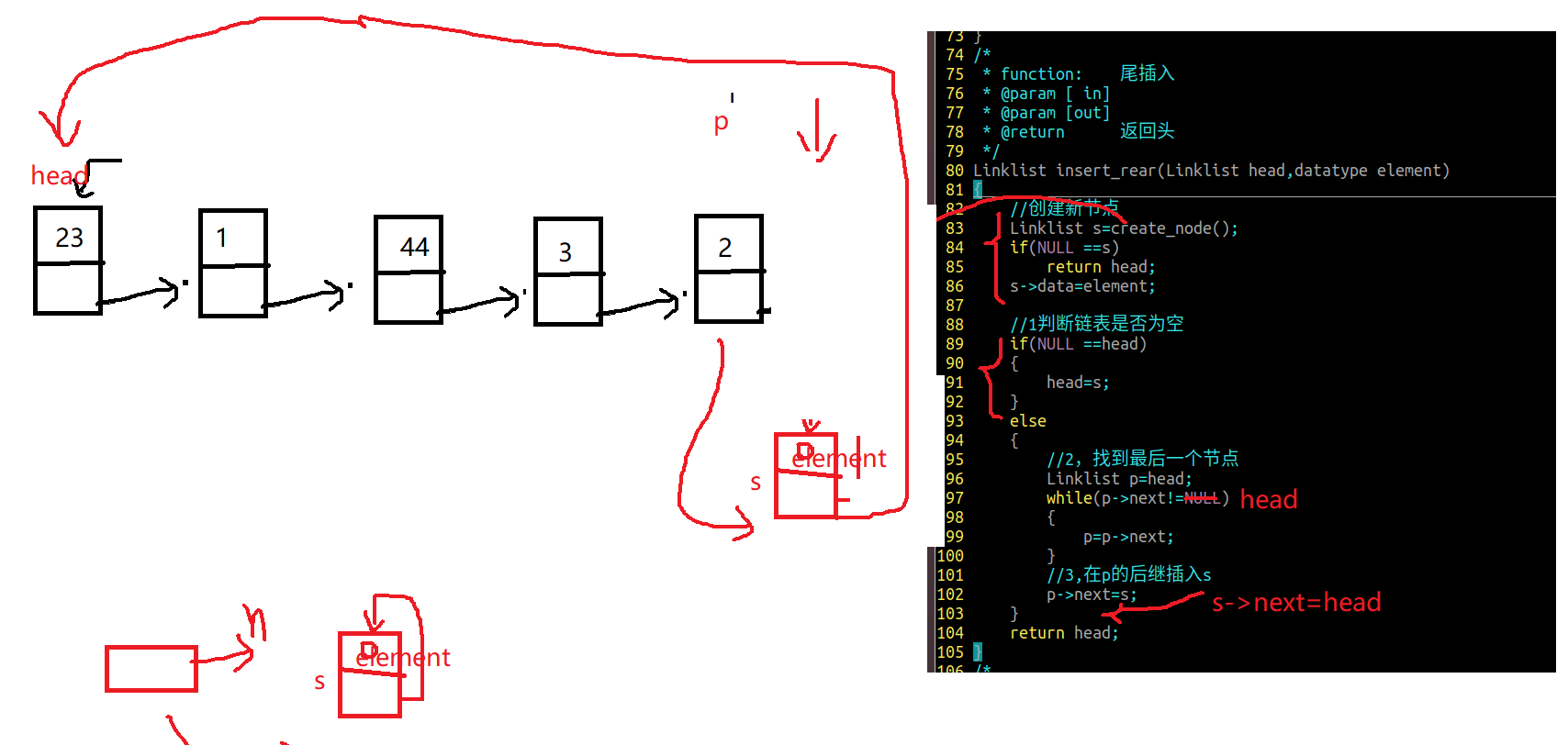
3.单向链表尾插
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 linklist insert_rear (linklist list ,datatype element) { linklist p=creat_node(); if (NULL ==p){ return list ; } p->data=element; if (NULL ==list ){ list =p; }else { linklist temp=list ; while (temp->next!=NULL ){ temp=temp->next; } temp->next=p; } return list ; }
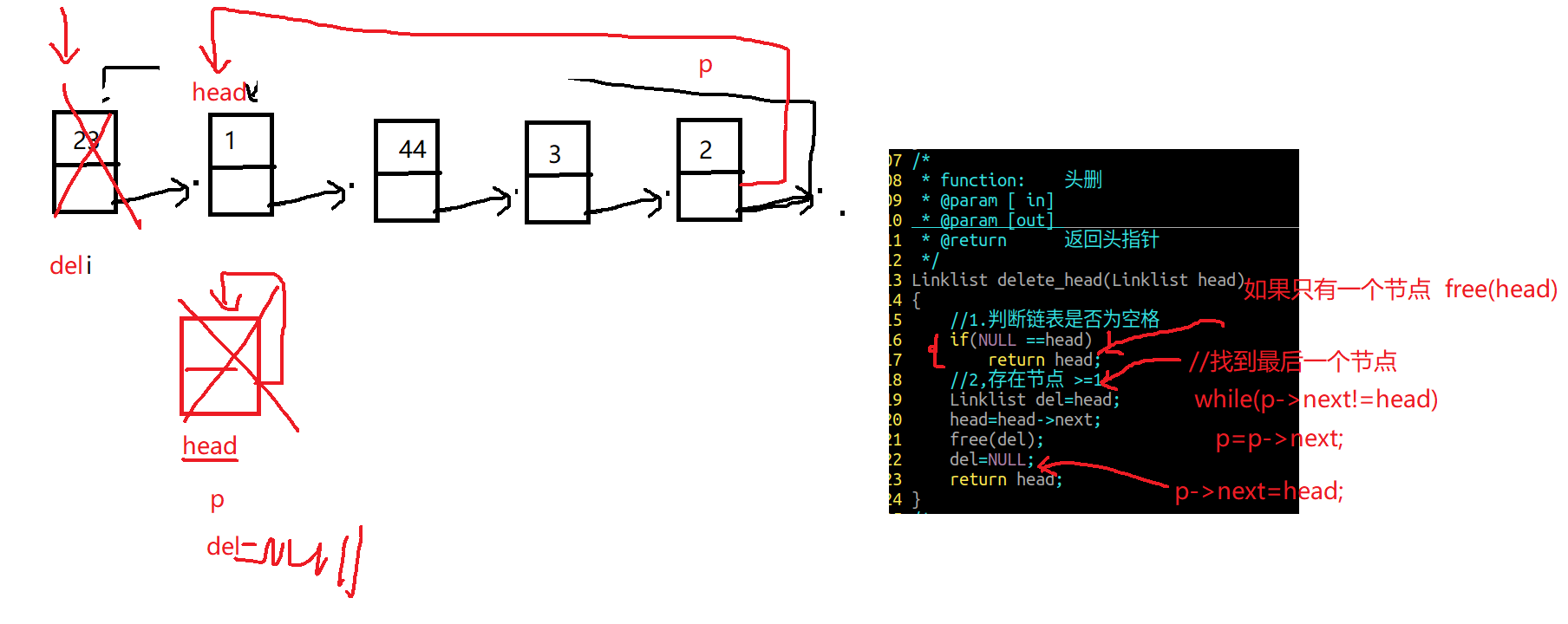
4.单向链表头删
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 linklist delete_head (linklist list ) { if (NULL ==list ) return list ; linklist del=list ; list =list ->next; free (del); del=NULL ; return list ; }
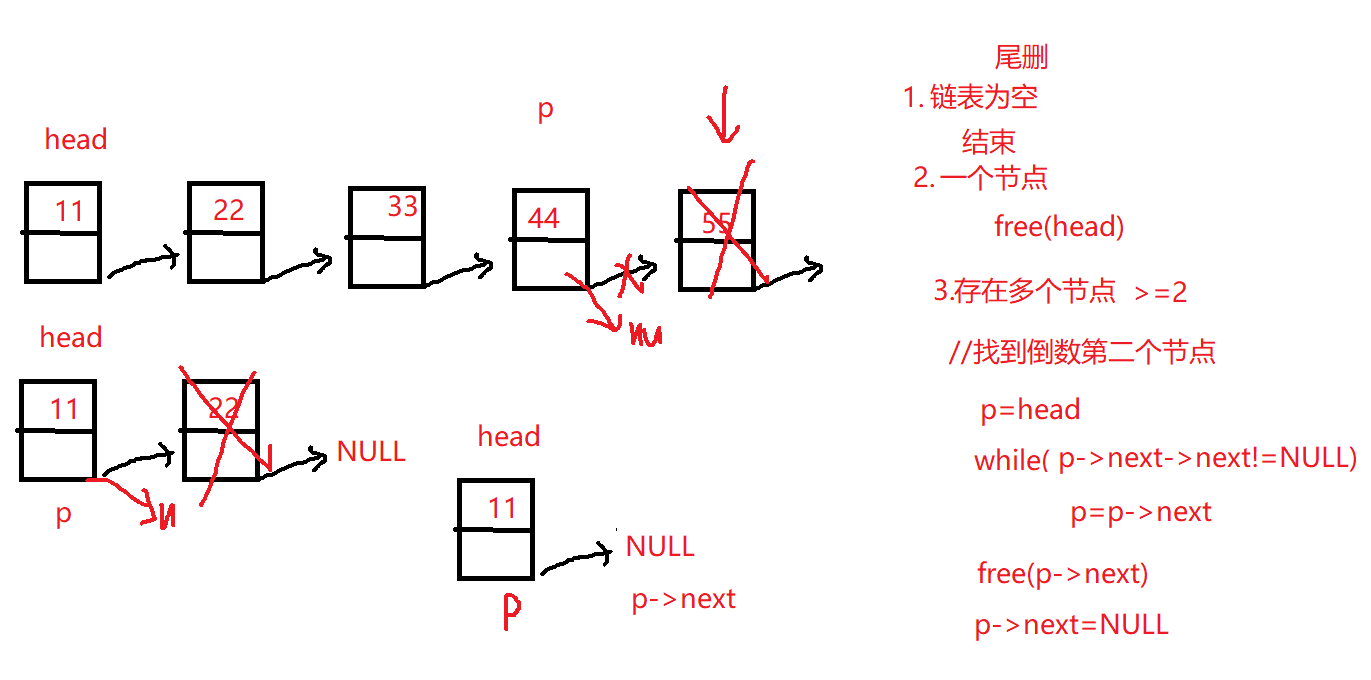
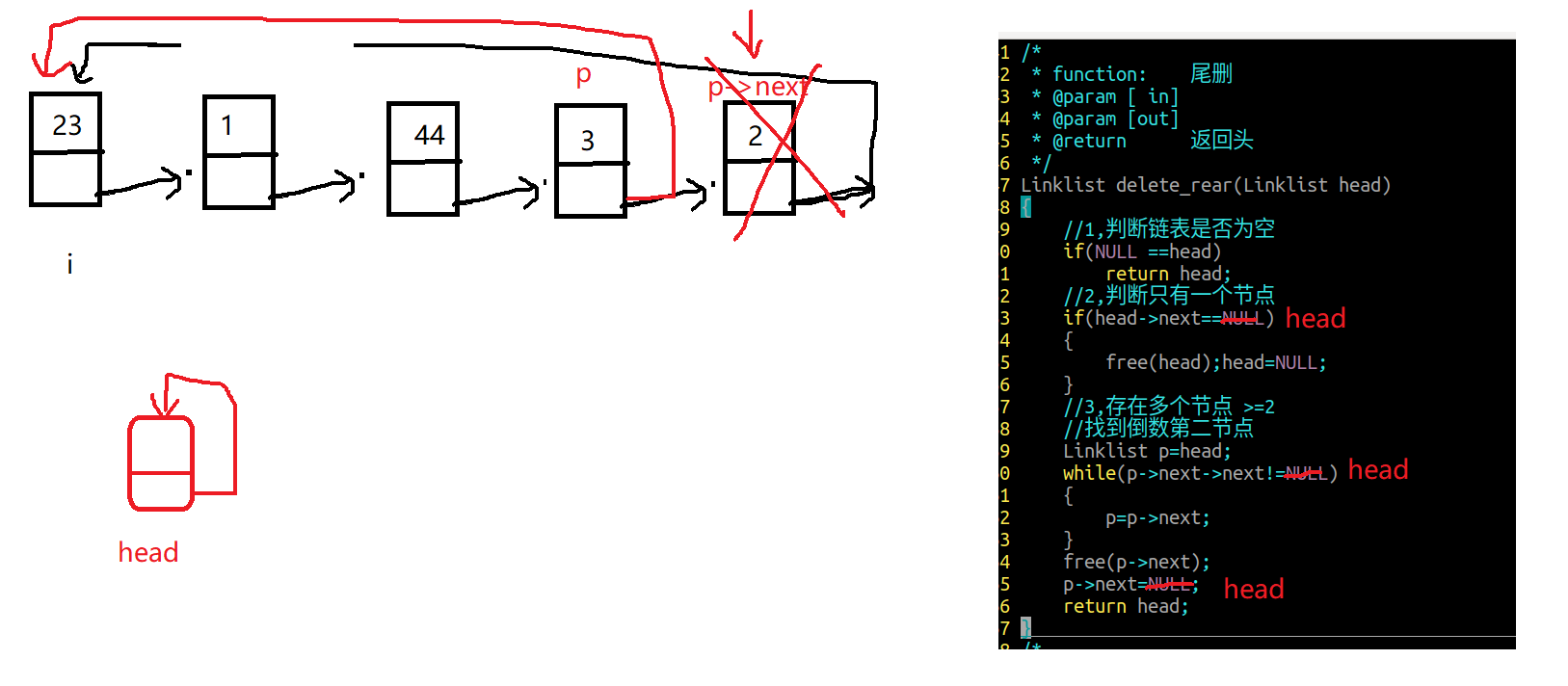
5.单向链表尾删
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 linklist delete_rear (linklist list ) { if (NULL ==list ) return NULL ; if (list ->next==NULL ){ free (list ); list =NULL ; return list ; }else { linklist p=list ; while (p->next->next!=NULL ){ p=p->next; } free (p->next); p->next=NULL ; } return list ; }
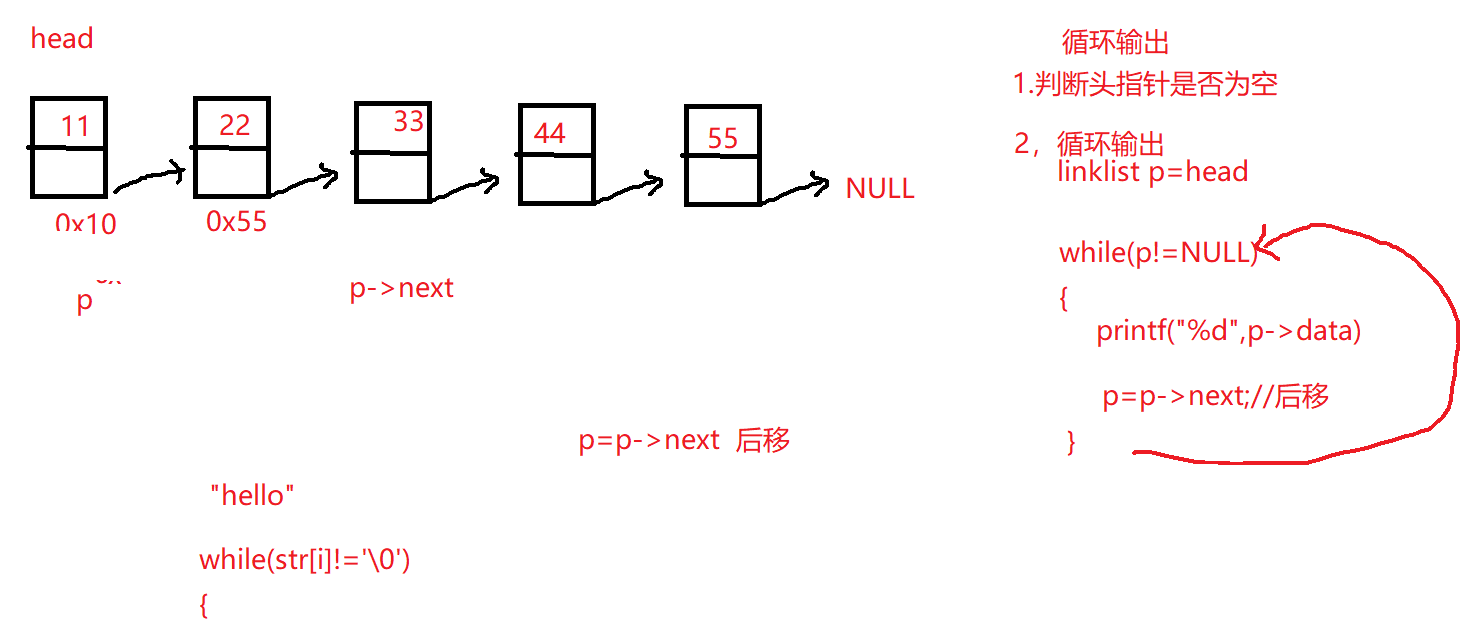
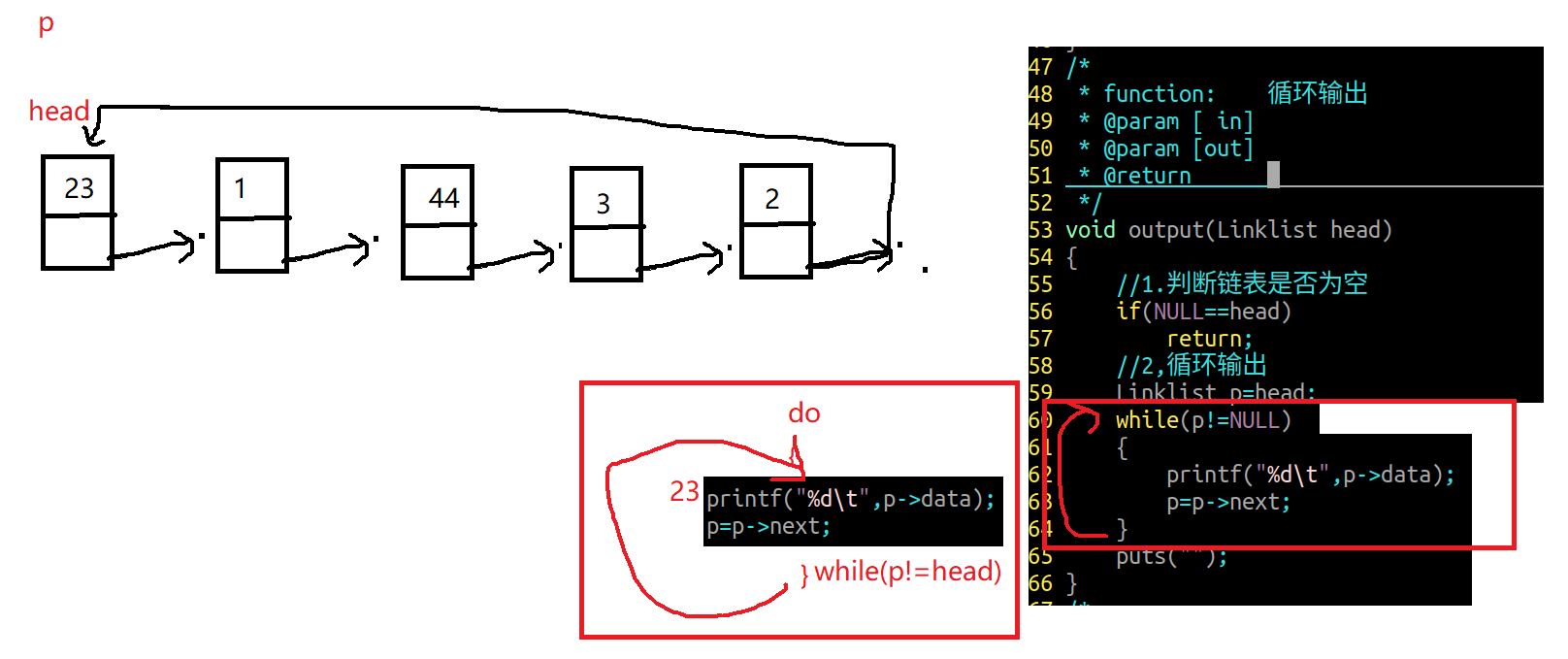
6.单向链表遍历
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 int len_linklist (linklist list ) { int count=0 ; while (list !=NULL ){ list =list ->next; count++; } return count; }
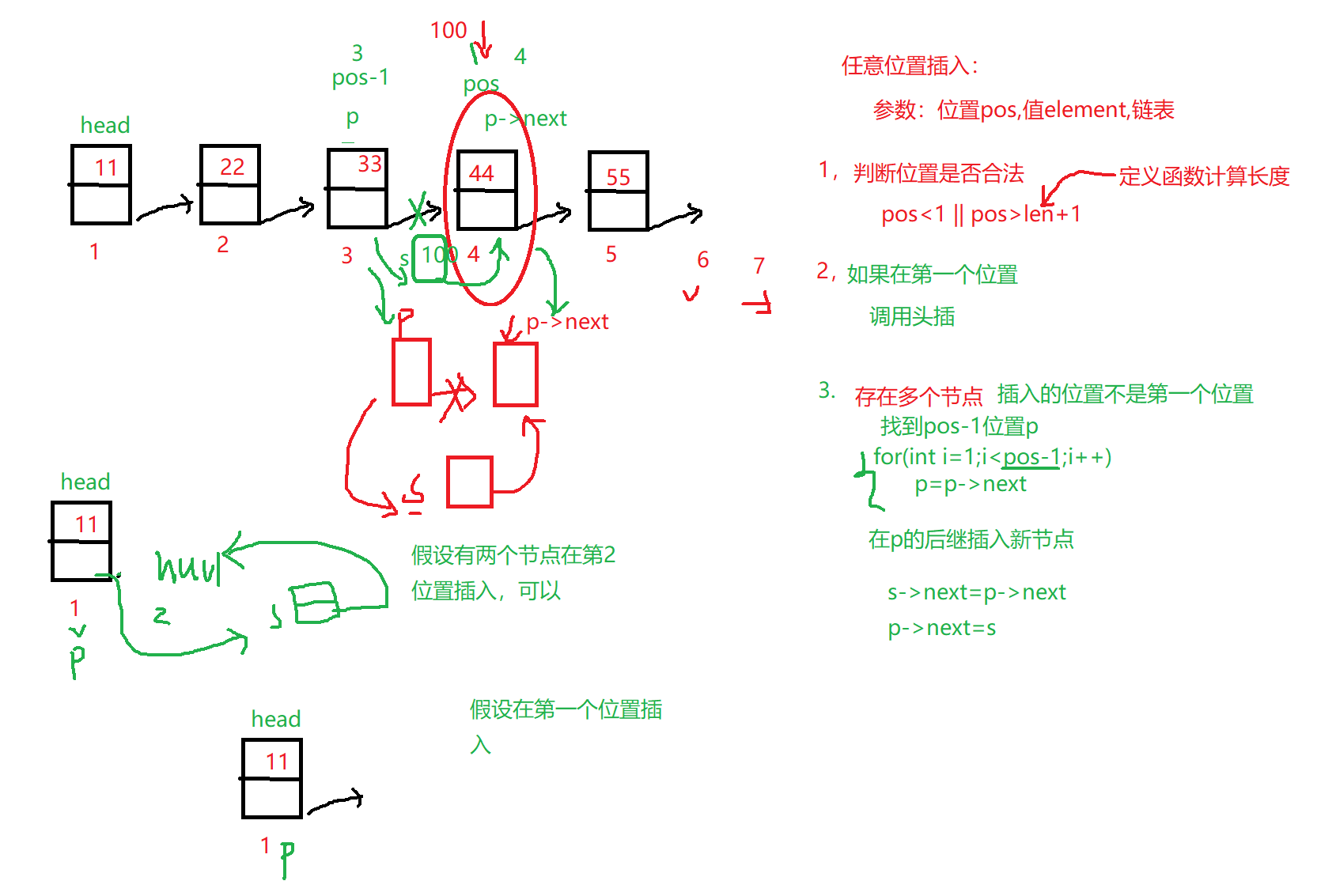
7.单向链表任意位置插入+计算长度
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 linklist insert_pos (linklist list ,int pos,datatype element) { if (pos<1 || pos>len_linklist(list )+1 ){ return list ; } if (pos==1 ){ return insert_head(list ,element); } linklist p=list ; for (int i = 1 ; i < pos-1 ; i++) { p=p->next; } linklist s=creat_node(); if (NULL ==s) return list ; s->data=element; s->next=p->next; p->next=s; return list ; }
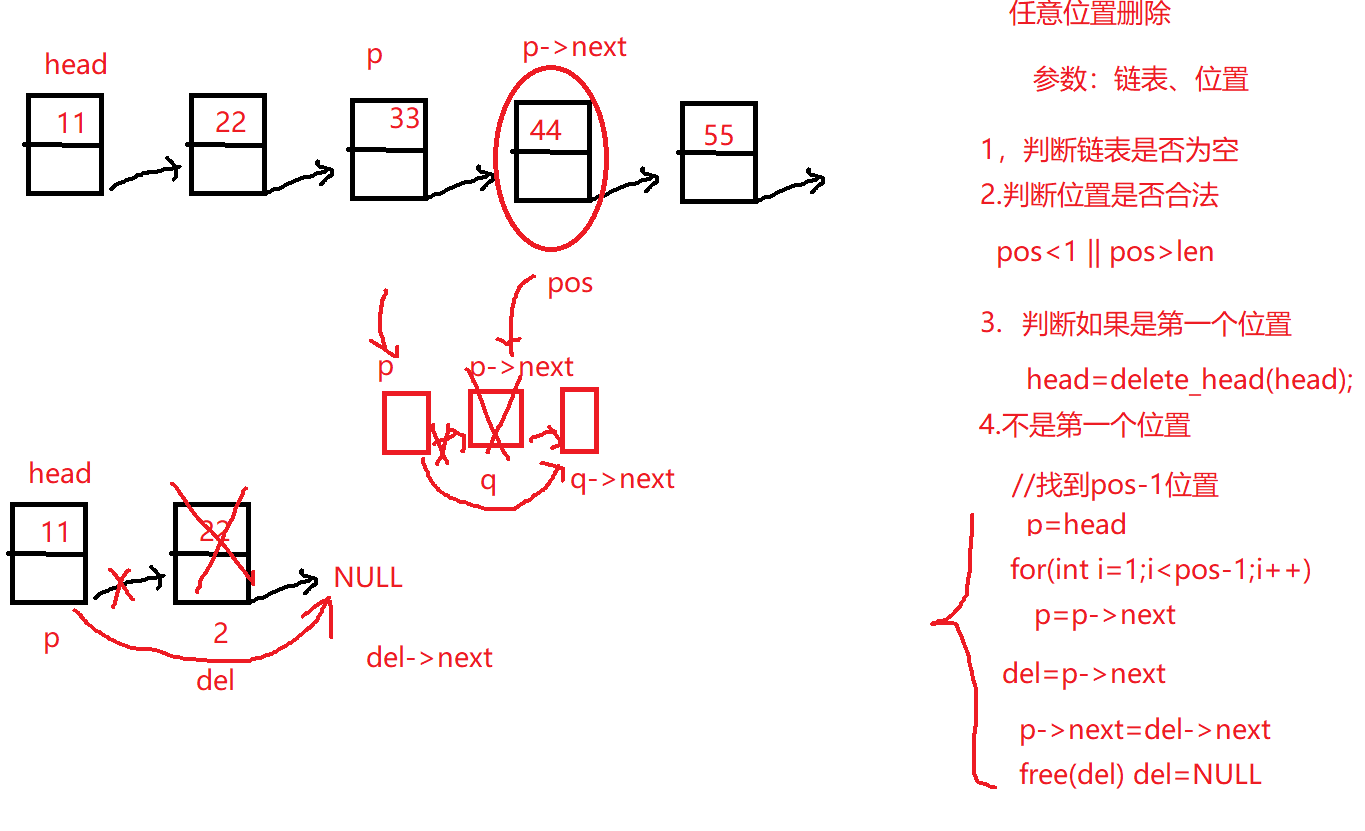
8.单向链表任意位置删除
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 linklist delete_pos (linklist list ,int pos) { if (NULL ==list ||pos<1 || pos>len_linklist(list )){ return list ; } if (pos==1 ){ return delete_head(list ); } linklist p = list ; for (int i = 1 ; i < pos-1 ; i++) { p=p->next; } linklist del=p->next; p->next=del->next; free (del); del=NULL ; return list ; }
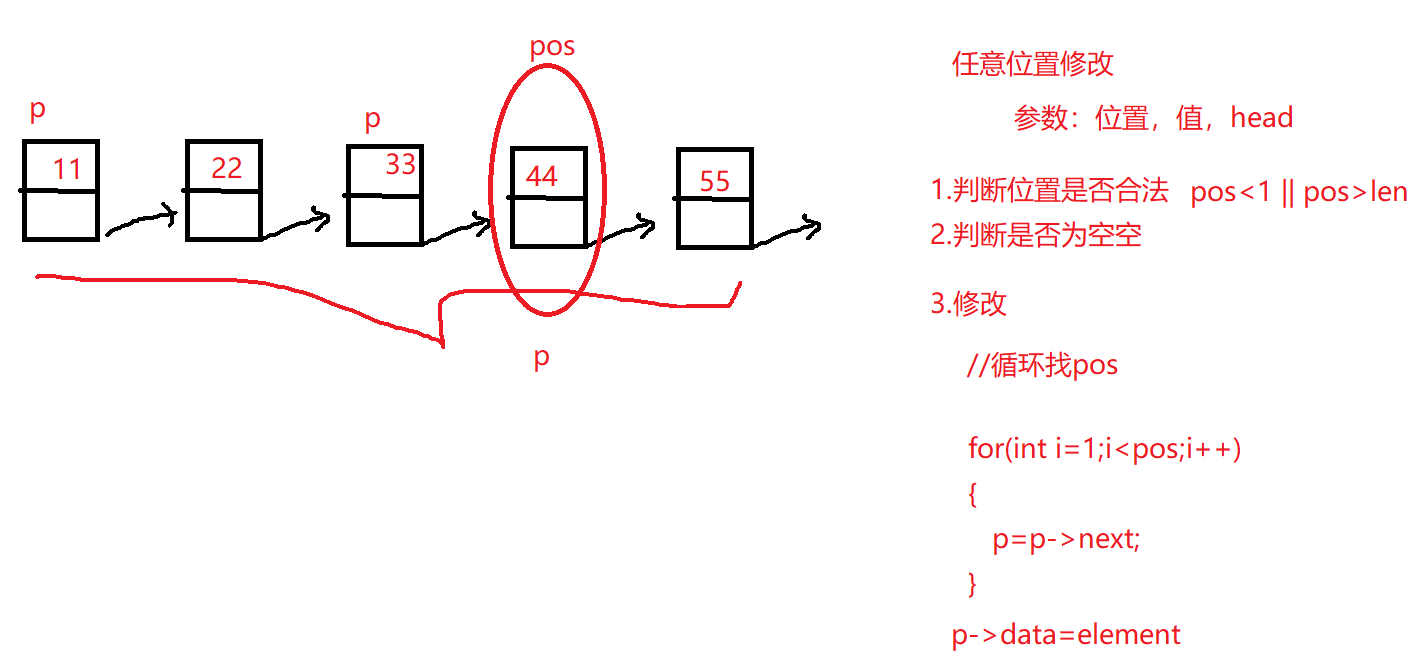
9.单向链表任意位置修改
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void update_pos (linklist list ,int pos,datatype element) { if (NULL ==list ||pos<1 ||pos>len_linklist(list )){ return ; } linklist p=list ; for (int i = 1 ; i < pos; i++) { p=p->next; } p->data=element; }
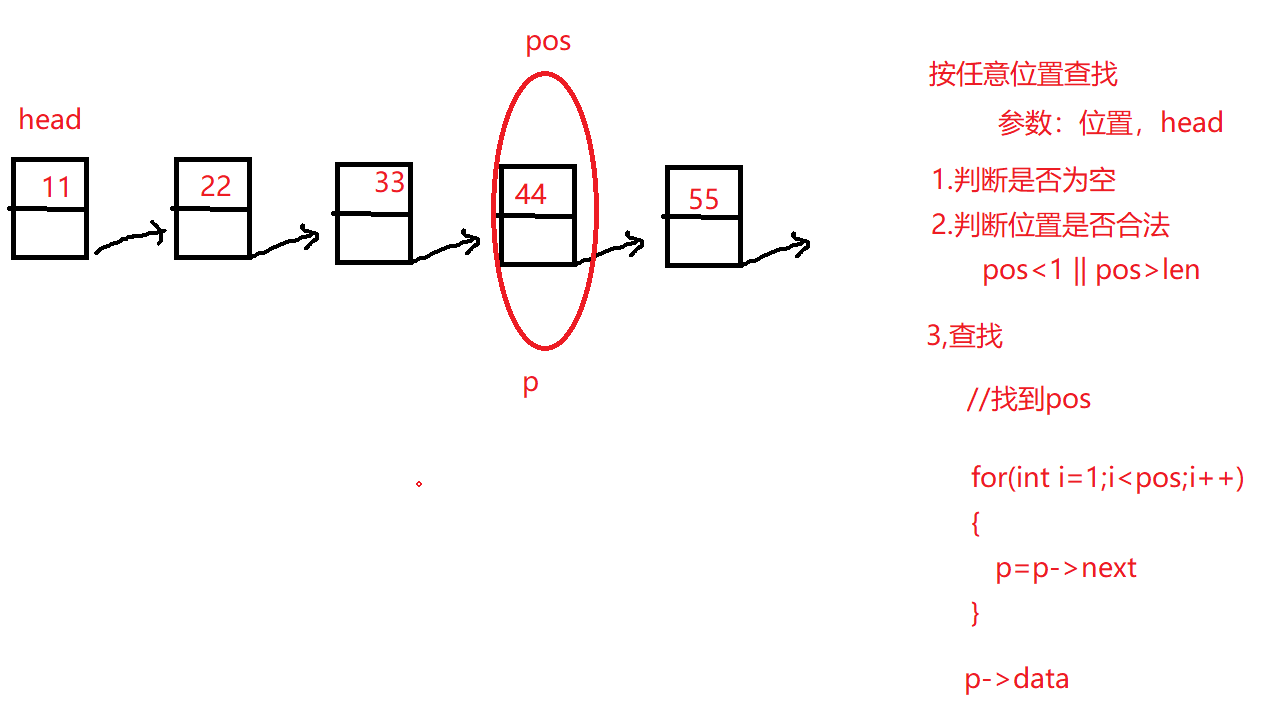
10.单向链表任意位置查找
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 datatype find_pos (linklist list ,int pos) { if (NULL ==list ||pos<1 ||pos>len_linklist(list )){ return error; } linklist p=list ; for (int i = 1 ; i < pos; i++) { p=p->next; } return p->data; }
11.单向链表任意元素查找
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 int search_data (Linklist head,datatype element) { if (NULL ==head) return FALSE; Linklist p=head; int count=0 ; while (p!=NULL ) { count++; if (p->data==element) return count; p=p->next; } return FALSE; }
12.单向链表任意元素修改
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 int update_data (Linklist head,datatype key,datatype element) { int pos=search_data(head,key); if (pos==FALSE) return FALSE; update_pos(head,pos,element); return SUCCESS; }
13.单向链表任意元素删除
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 Linklist delete_data (Linklist head,datatype key) { int pos=search_data(head,key); if (pos==FALSE) return head; head=delete_pos(head,pos); return head; }
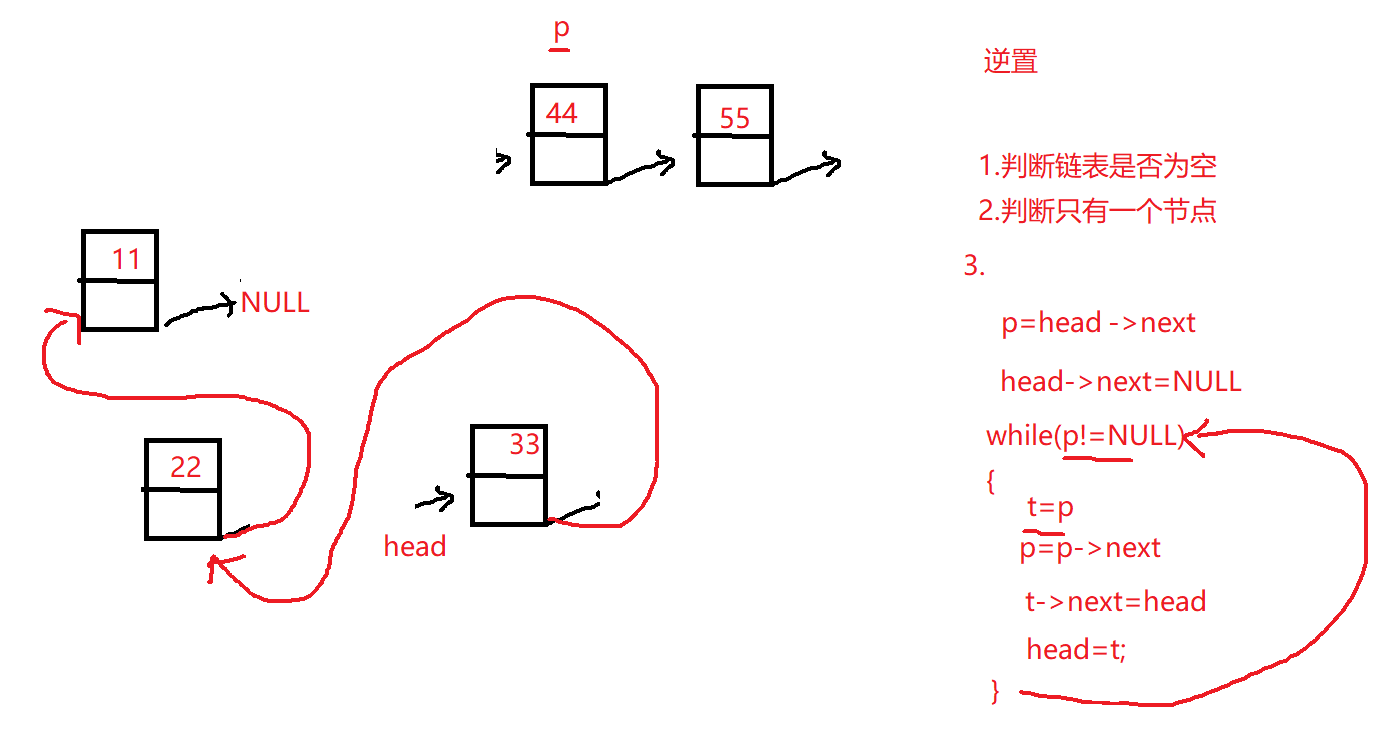
14.单向链表逆置(面试)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 linklist invert (linklist list ) { if (NULL ==list || NULL ==list ->next) return list ; linklist p=list ->next; list ->next=NULL ; while (p!=NULL ){ linklist temp=p; p=p->next; temp->next=list ; list =temp; } return list ; }
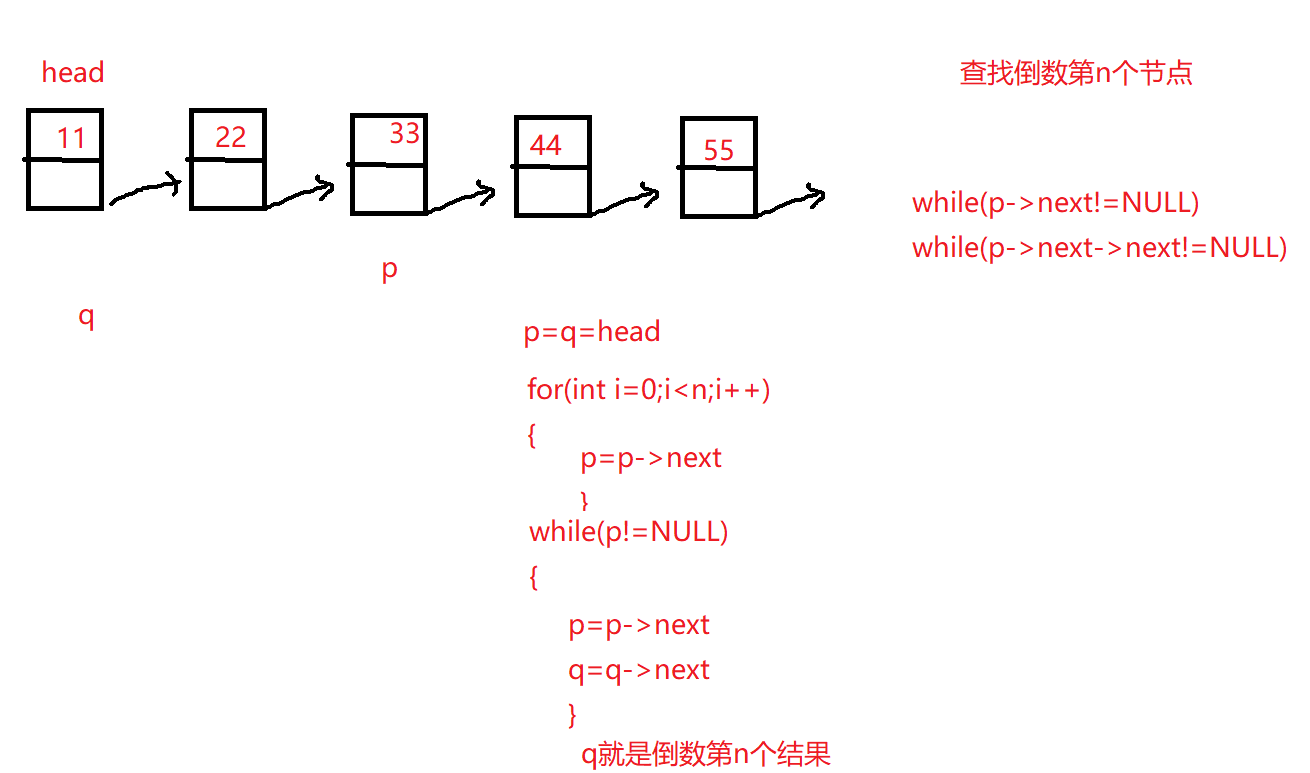
15.单向链表查找倒数第n个节点(面试)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 void search_n (Linklist head,int n) { if (NULL ==head || n<1 || n>length(head)) return ; Linklist p=head,q=head; for (int i=0 ;i<n;i++) { q=q->next; } while (q!=NULL ) { p=p->next; q=q->next; } printf ("search data is %d\n" ,p->data); }
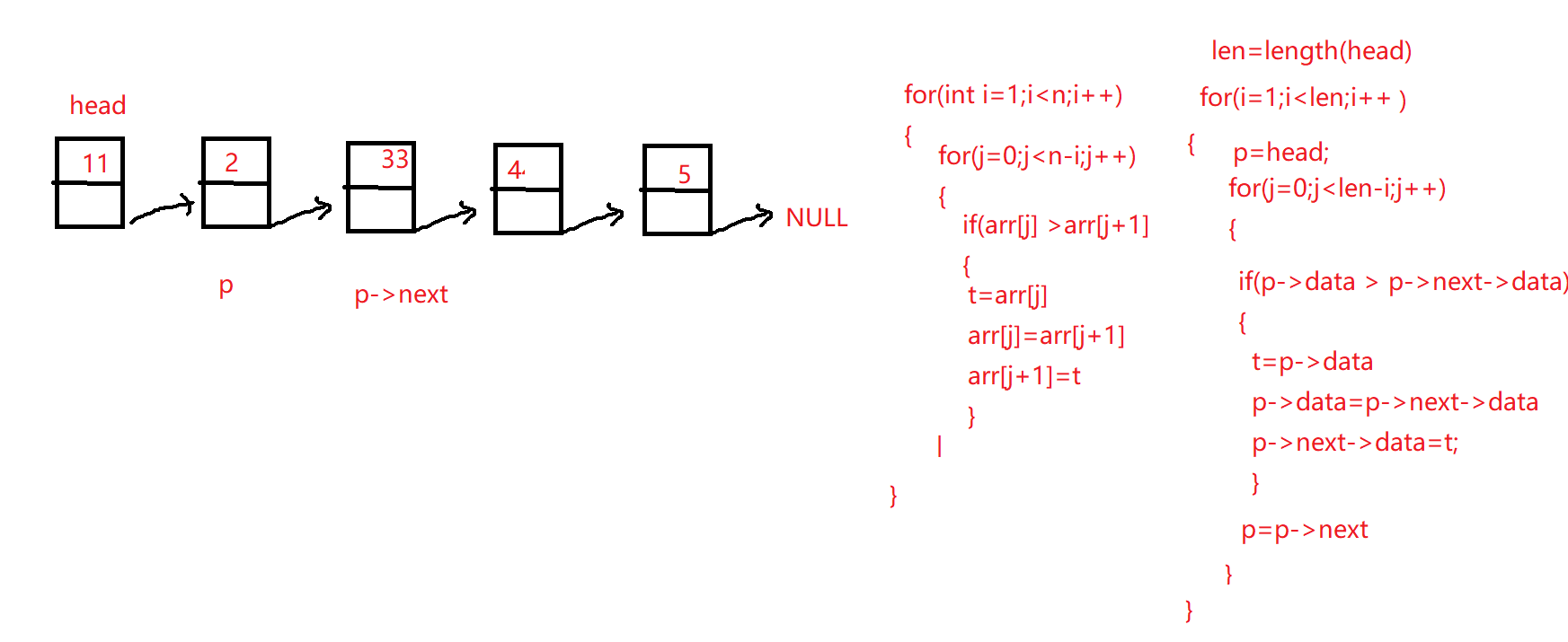
16.单向链表排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 void Bubble (Linklist head) { if (NULL ==head) return ; for (Linklist i=head;i->next!=NULL ;i=i->next) { Linklist min=i; for (Linklist j=i->next;j!=NULL ;j=j->next) { if (min->data>j->data) { min=j; } } datatype t=min->data; min->data=i->data; i->data=t; } }
17.单向链表释放内存
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 Linklist free_space (Linklist head) { if (NULL ==head) return head; Linklist p=head; while (p!=NULL ) { p=delete_head(p); } head=NULL ; return head; }
四、单向循环链表
1> 单向循环链表概念
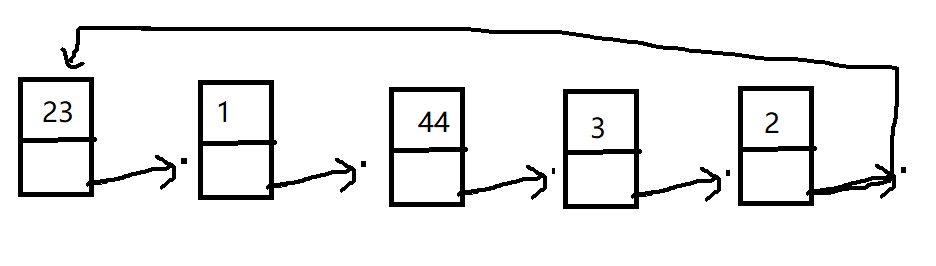
引入目的:单向链表只能单向遍历,所以引出单向循环链表(单曲循环)
单向循环链表:尾节点的指针域指向第一个节点的地址
2> 单向循环链表的操作
2.1 单向循环链表节点创建
2.2 单向循环链表的头插
2.3 单向循环链表的头删
2.4 单向循环链表的尾插
2.5 单向循环链表的尾删
2.6 单向循环链表遍历
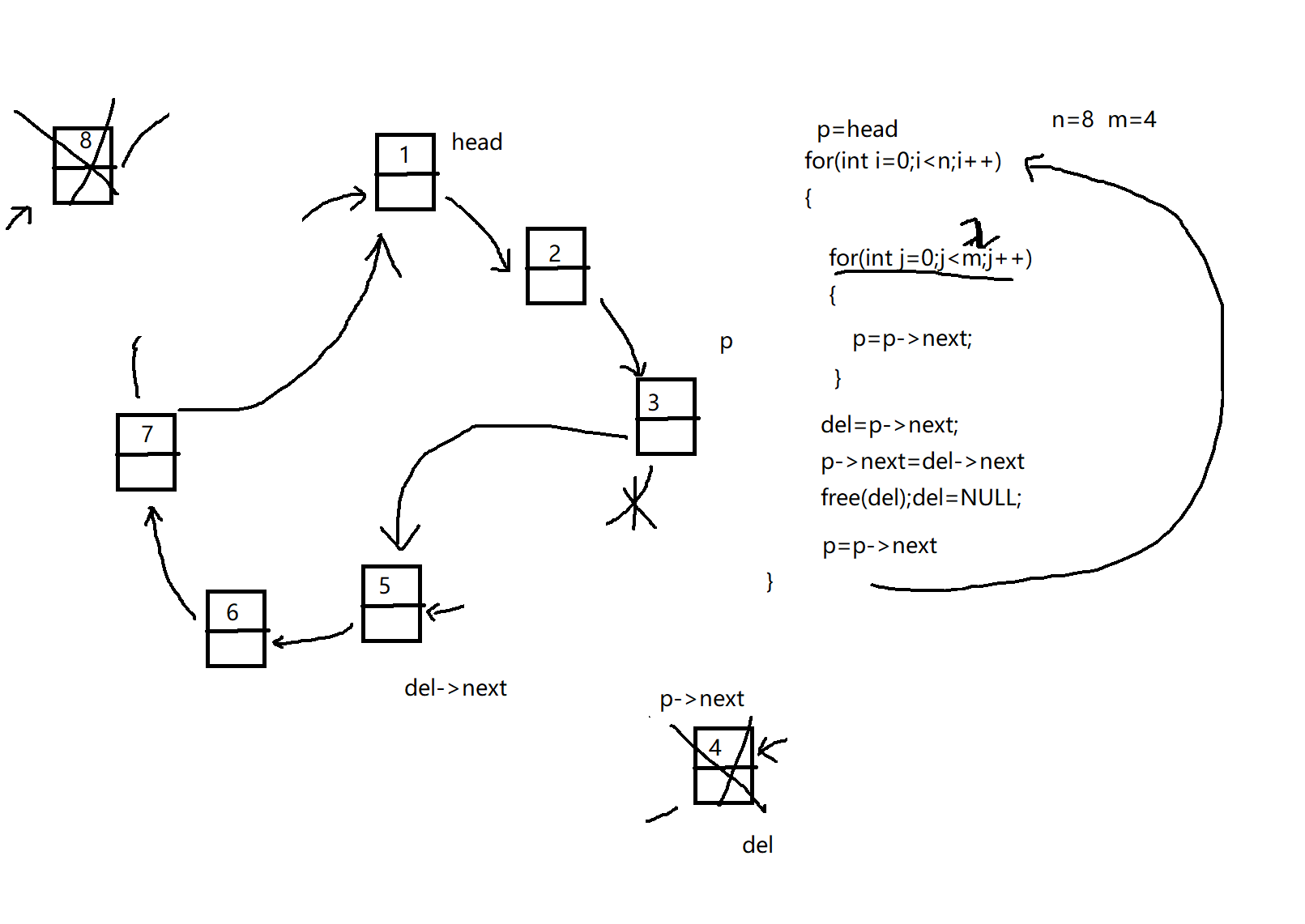
2.7 约瑟夫环
约瑟夫环:用循环链表编程实现约瑟夫问题
n个人围成一圈,从某人开始报数1, 2, …, m,数到m的人出圈,然后从出圈的下一个人(m+1)开始重复此过程,
直到 全部人出圈,于是得到一个出圈人员的新序列
如当n=8,m=4时,若从第一个位置数起,则所得到的新的序列 为4, 8, 5, 2, 1, 3, 7, 6。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 Linklist joseph (Linklist head,int n,int m) { if (NULL ==head) return head; Linklist p=head; for (int i=0 ;i<n;i++) { for (int j=0 ;j<m-2 ;j++) { p=p->next; } Linklist del=p->next; printf ("%d\t" ,del->data); p->next=del->next; free (del); del=NULL ; p=p->next; } return head; }
五、双向链表
1> 双向链表概念
单向链表不可以查找前一个节点的地址,所以引出双向链表
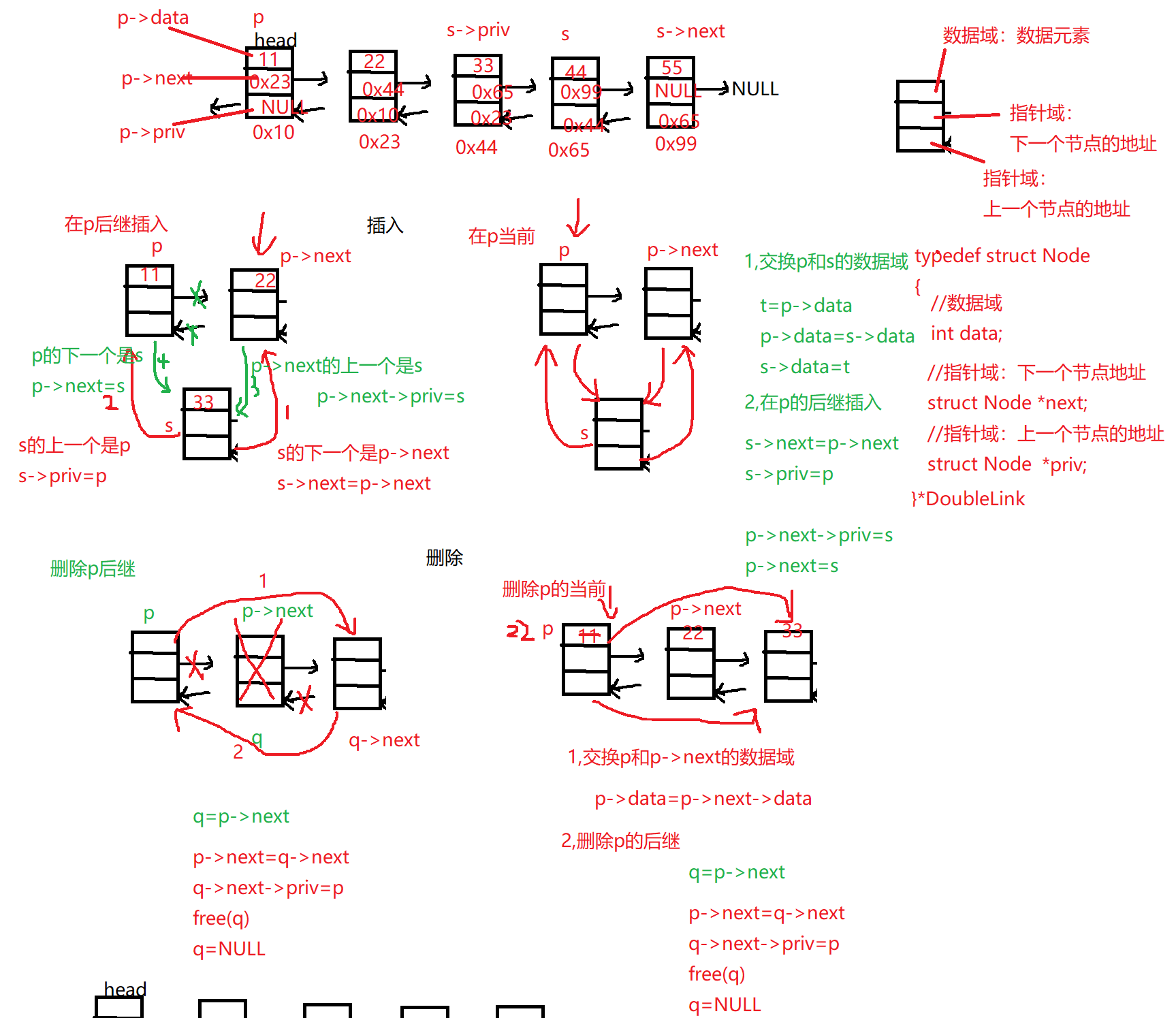
双向链表:节点存在两个指针域,一个指向下一个节点的地址,一个指针上一个节点的地址
1.1 节点的认识
1.2 链表的插入和删除
2> 双向链表操作
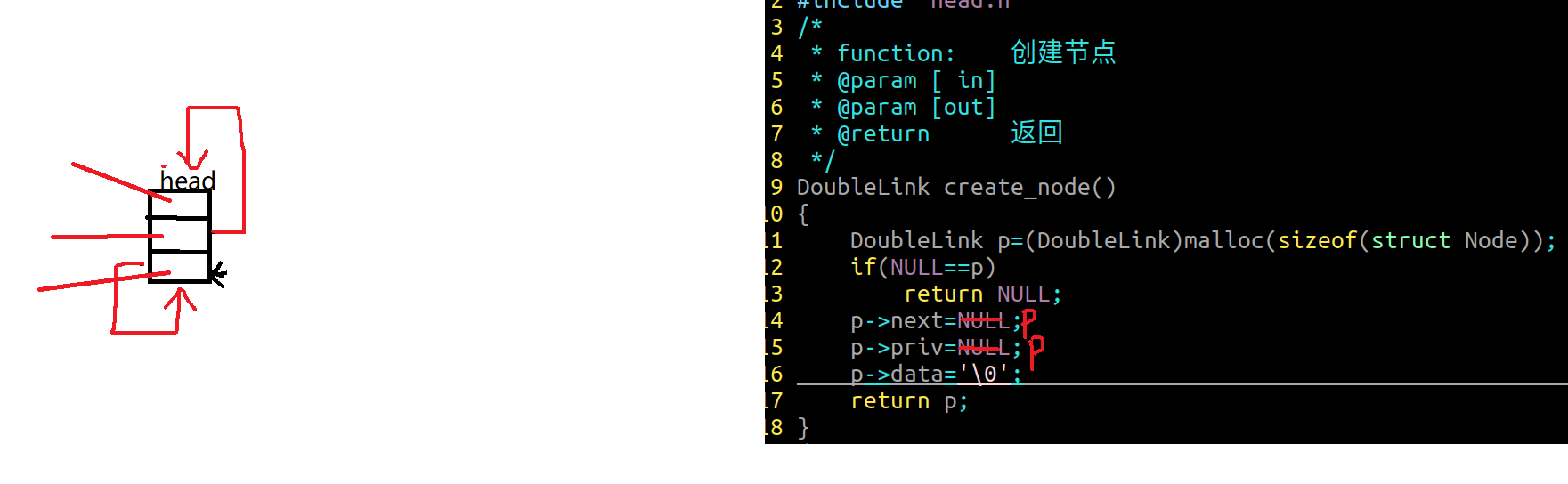
2.1 双向链表节点创建
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 DoubleLink create_node () { DoubleLink p=(DoubleLink)malloc (sizeof (struct Node)); if (NULL ==p) return NULL ; p->next=NULL ; p->priv=NULL ; p->data='\0' ; return p; }
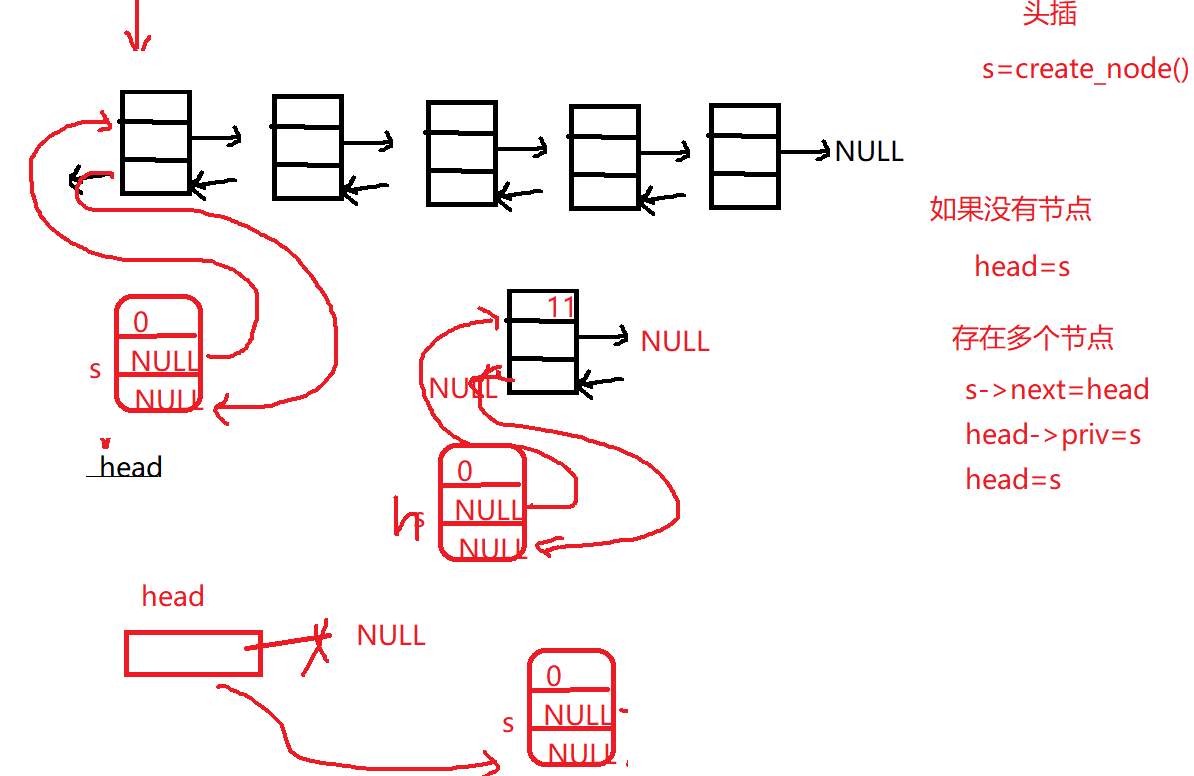
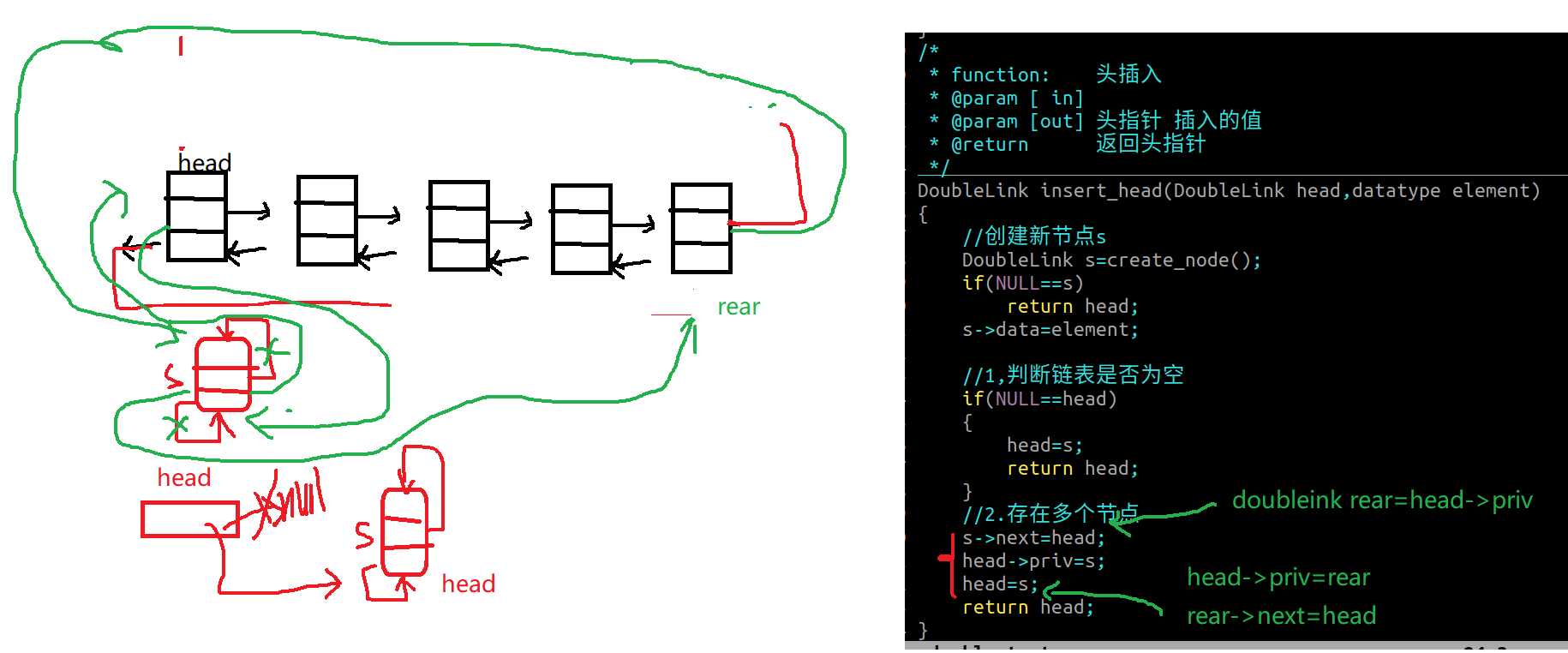
2.2 双向链表头插
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 DoubleLink insert_head (DoubleLink head,datatype element) { DoubleLink s=create_node(); if (NULL ==s) return head; s->data=element; if (NULL ==head) { head=s; return head; } s->next=head; head->priv=s; head=s; return head; }
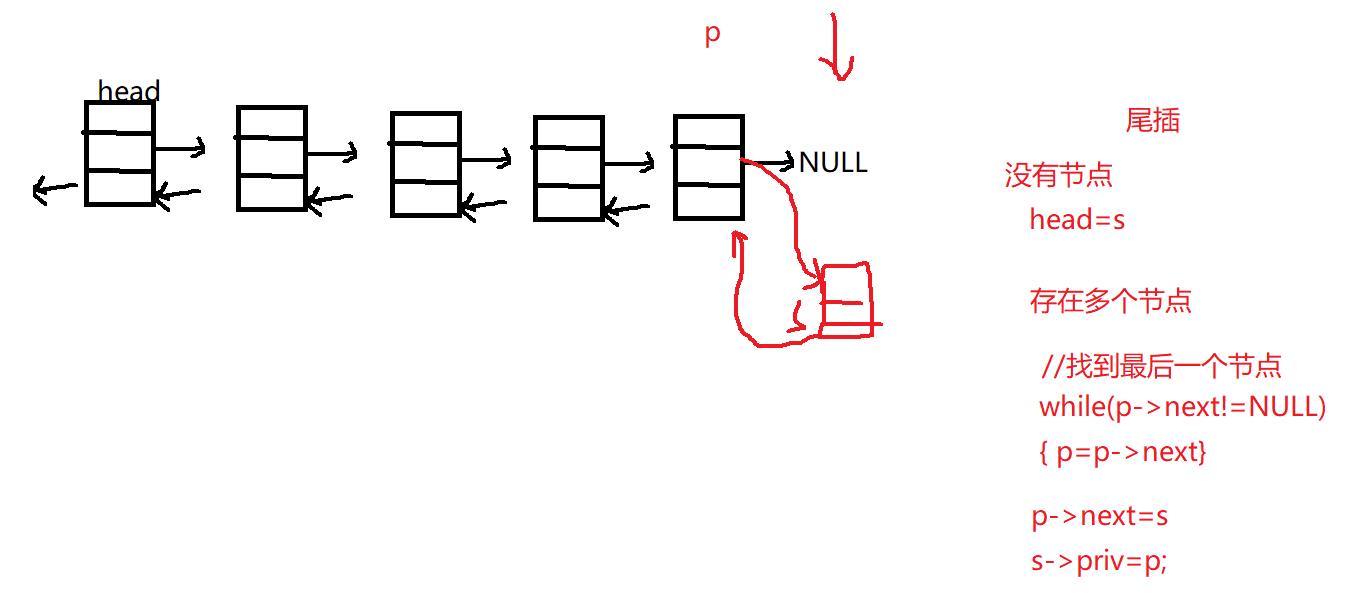
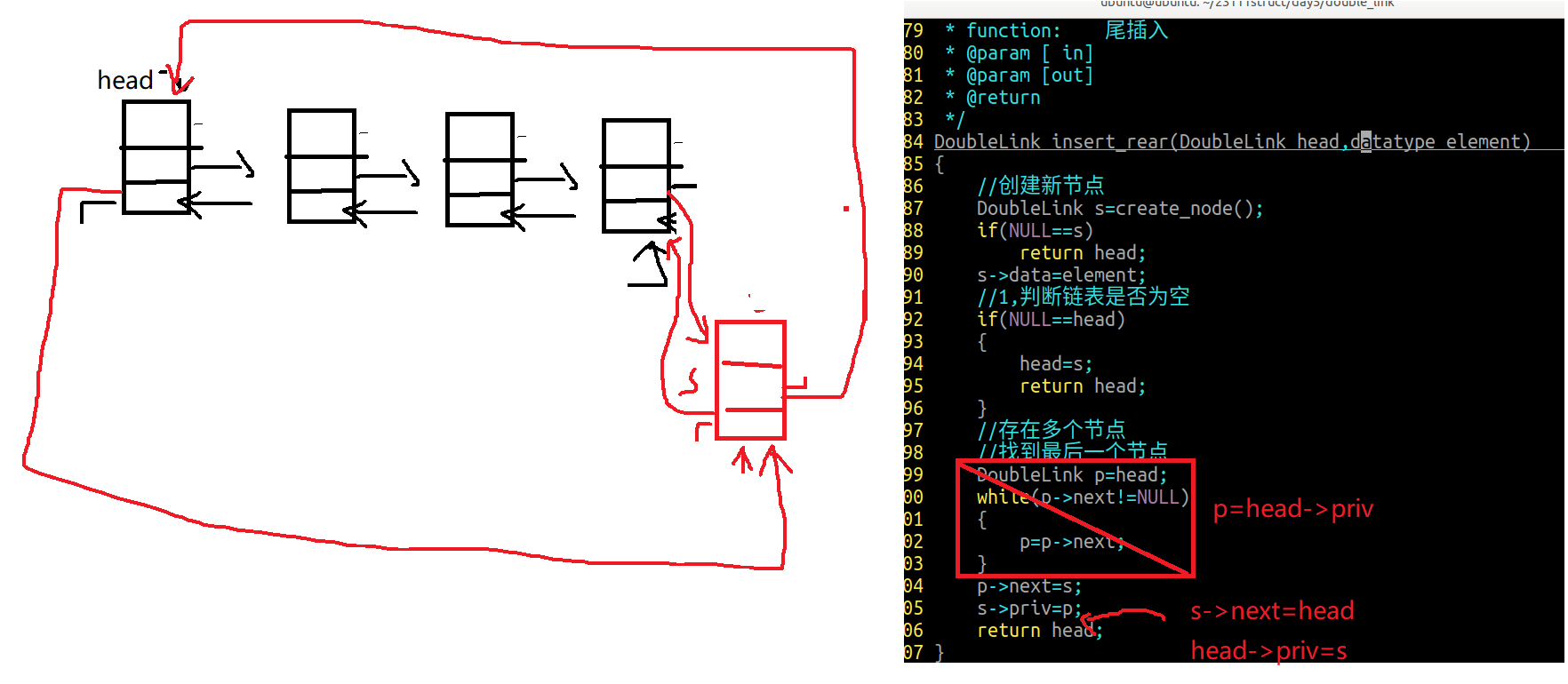
2.3 双向链表尾插
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 DoubleLink insert_rear (DoubleLink head,datatype element) { DoubleLink s=create_node(); if (NULL ==s) return head; s->data=element; if (NULL ==head) { head=s; return head; } DoubleLink p=head; while (p->next!=NULL ) { p=p->next; } p->next=s; s->priv=p; return head; }
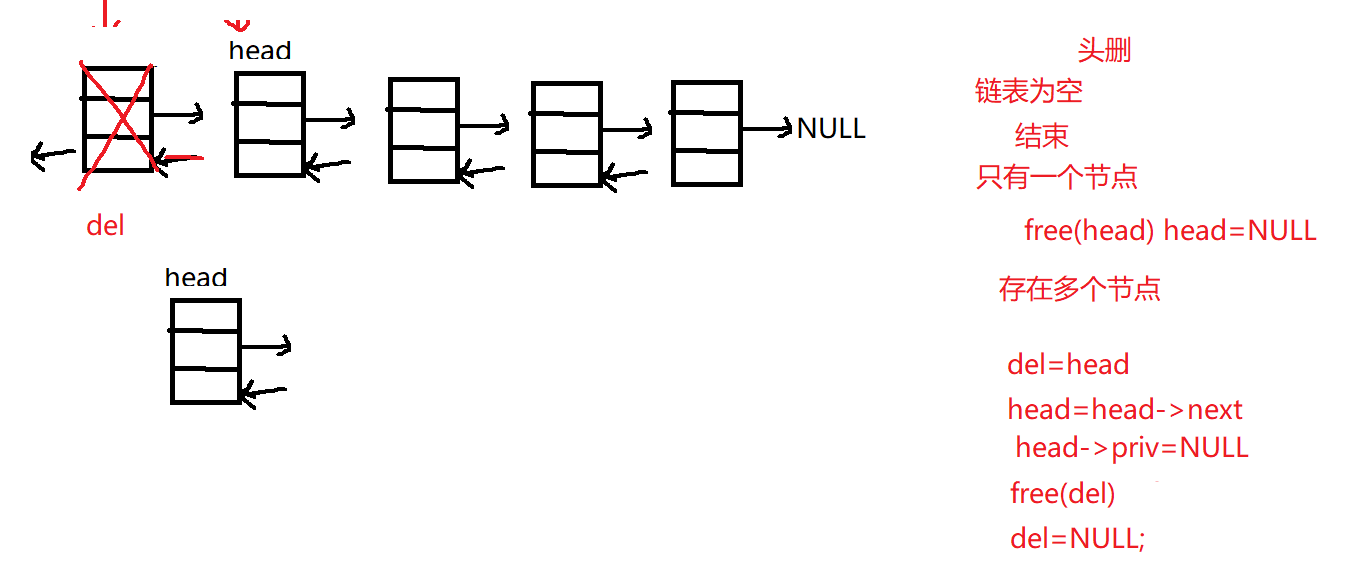
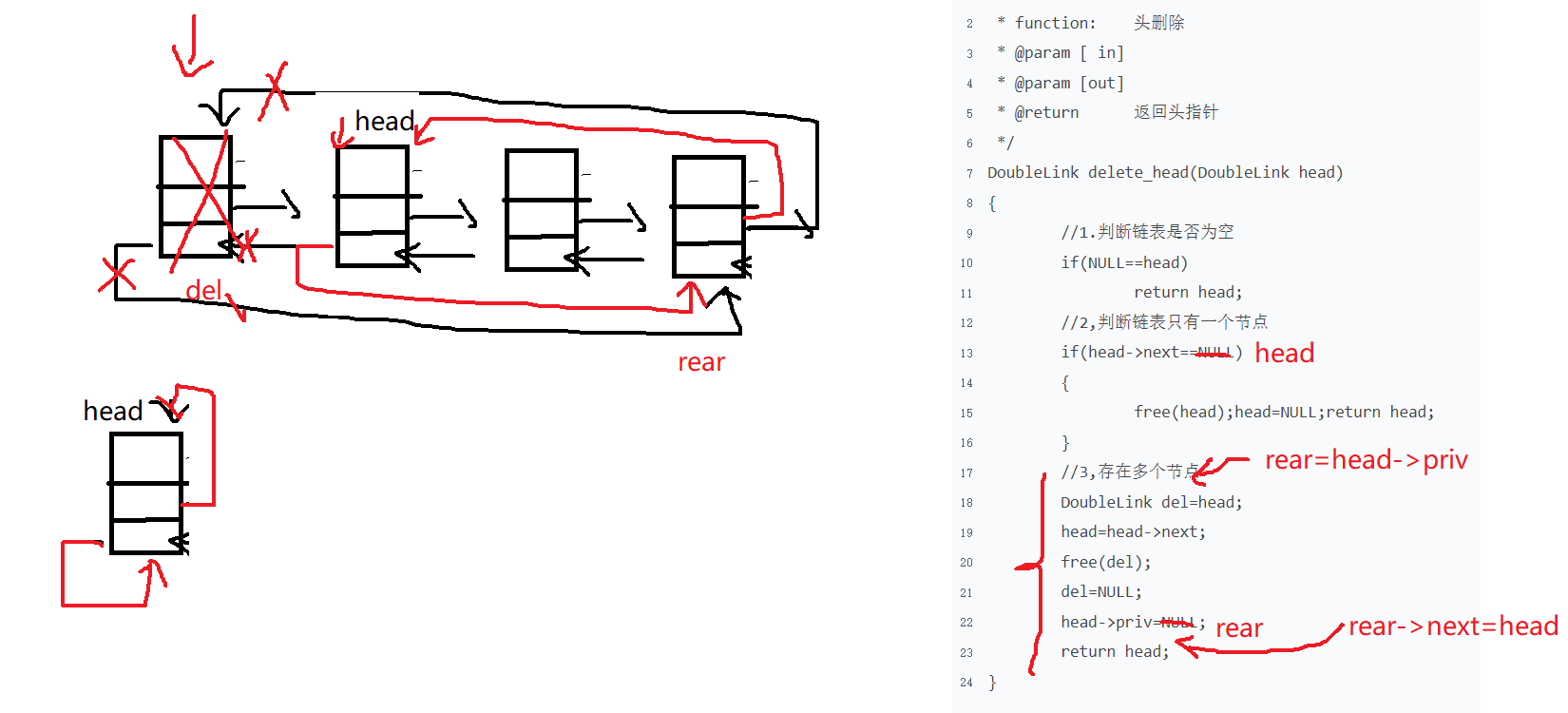
2.4 双向链表头删
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 DoubleLink delete_head (DoubleLink head) { if (NULL ==head) return head; if (head->next==NULL ) { free (head);head=NULL ;return head; } DoubleLink del=head; head=head->next; free (del); del=NULL ; head->priv=NULL ; return head; }
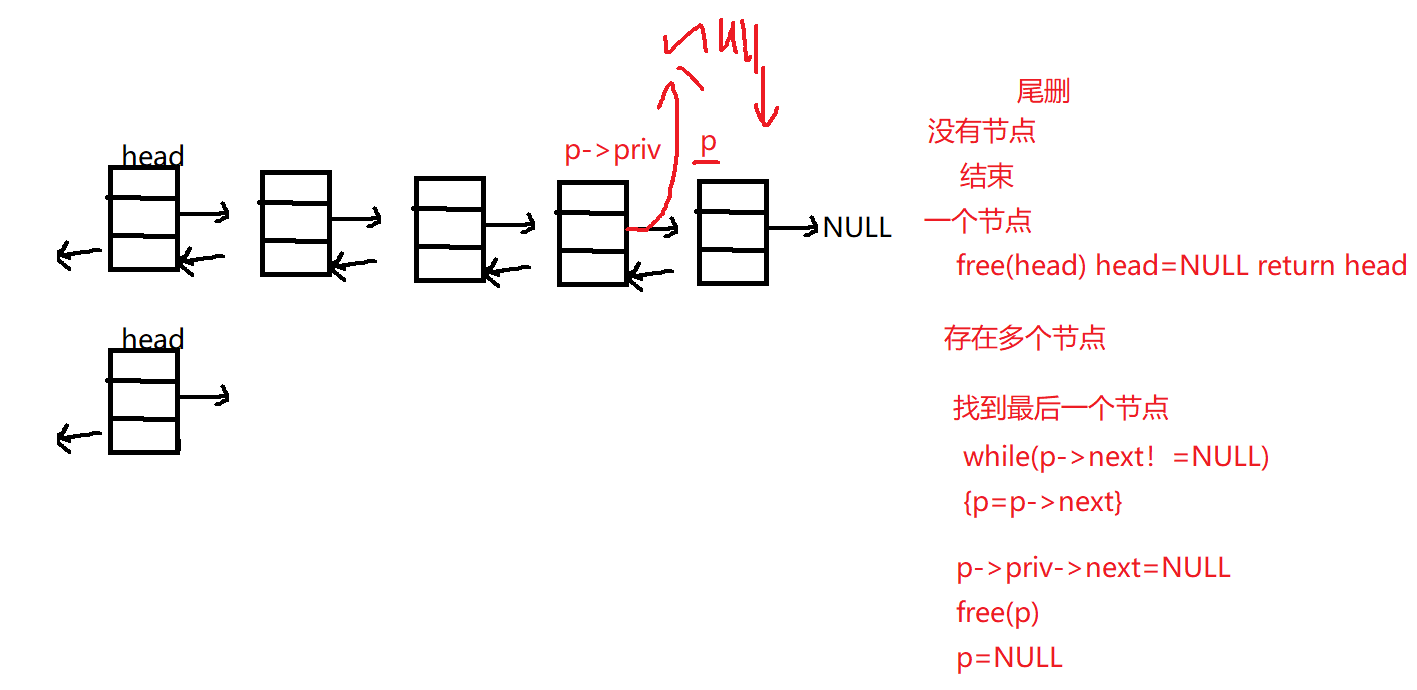
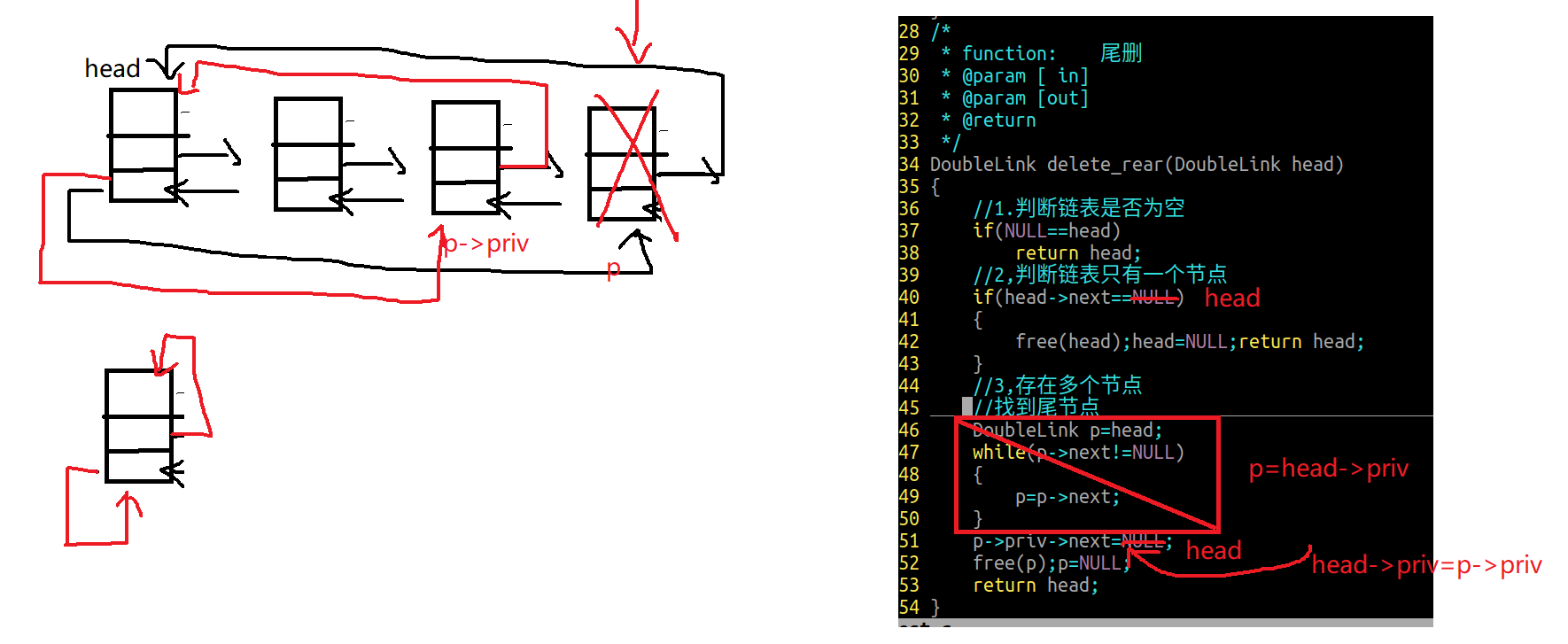
2.5 双向链表尾删
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 DoubleLink delete_rear (DoubleLink head) { if (NULL ==head) return head; if (head->next==NULL ) { free (head);head=NULL ;return head; } DoubleLink p=head; while (p->next!=NULL ) { p=p->next; } p->priv->next=NULL ; free (p);p=NULL ; return head; }
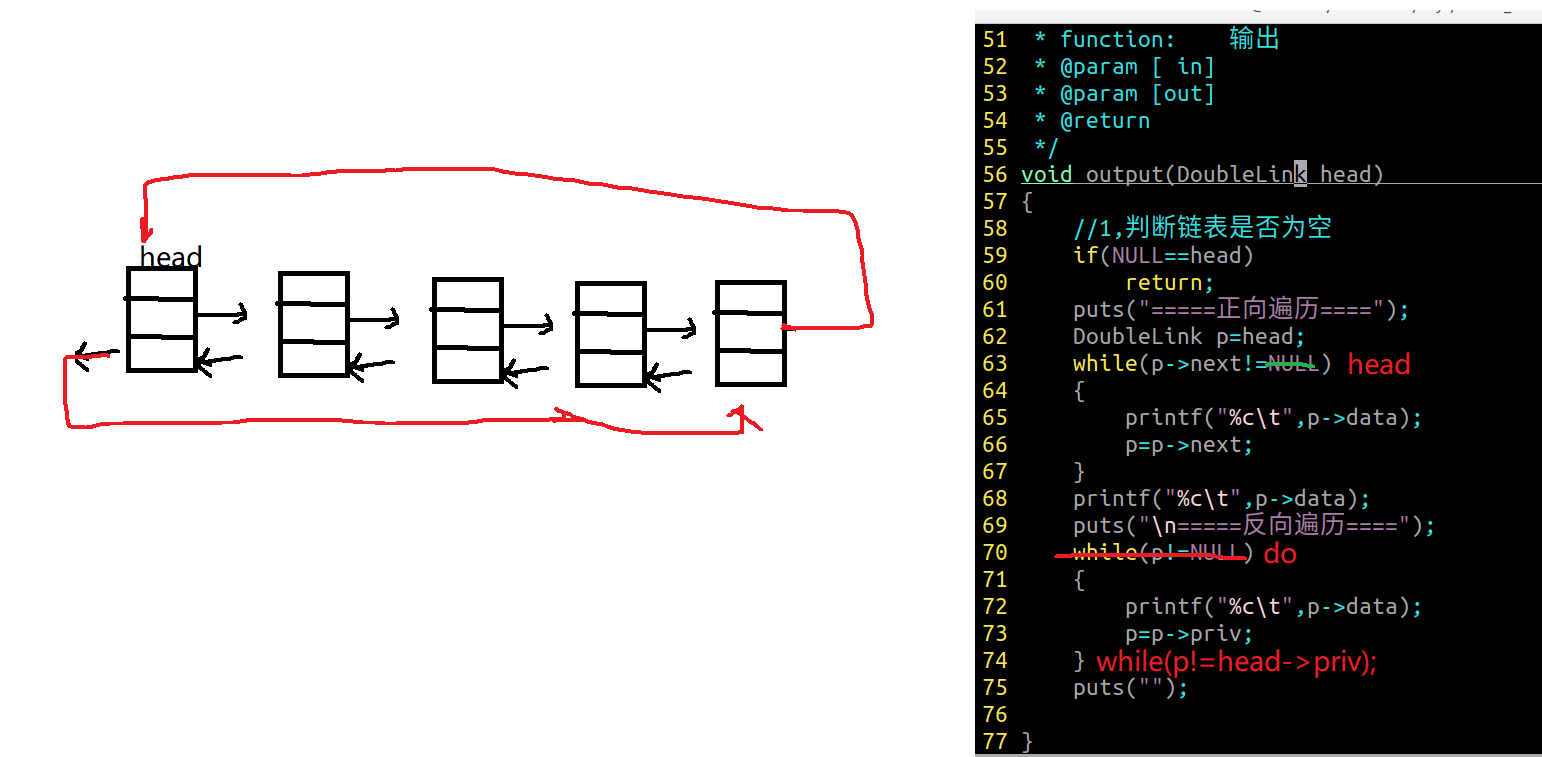
2.6 双向链表遍历
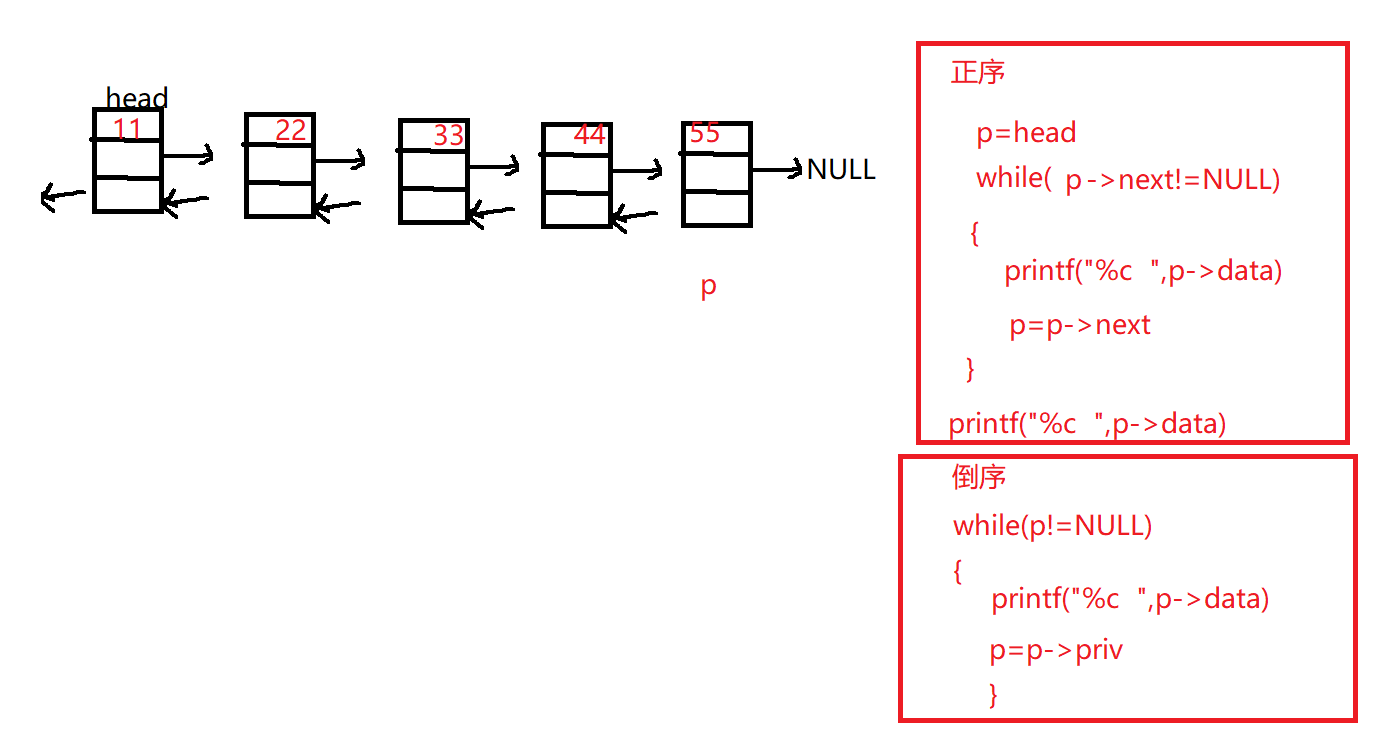
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 c void output (DoubleLink head) { if (NULL ==head) return ; puts ("=====正向遍历====" ); DoubleLink p=head; while (p->next!=NULL ) { printf ("%c\t" ,p->data); p=p->next; } printf ("%c\t" ,p->data); puts ("\n=====反向遍历====" ); while (p!=NULL ) { printf ("%c\t" ,p->data); p=p->priv; } puts ("" ); }
六、双向循环链表
1> 双向循环链表的节点创建
2> 双向循环链表头插
3> 双向循环链表遍历
4> 双向循环链表尾插
5> 双向循环链表头删
6> 双向循环链表尾删
七、栈stack
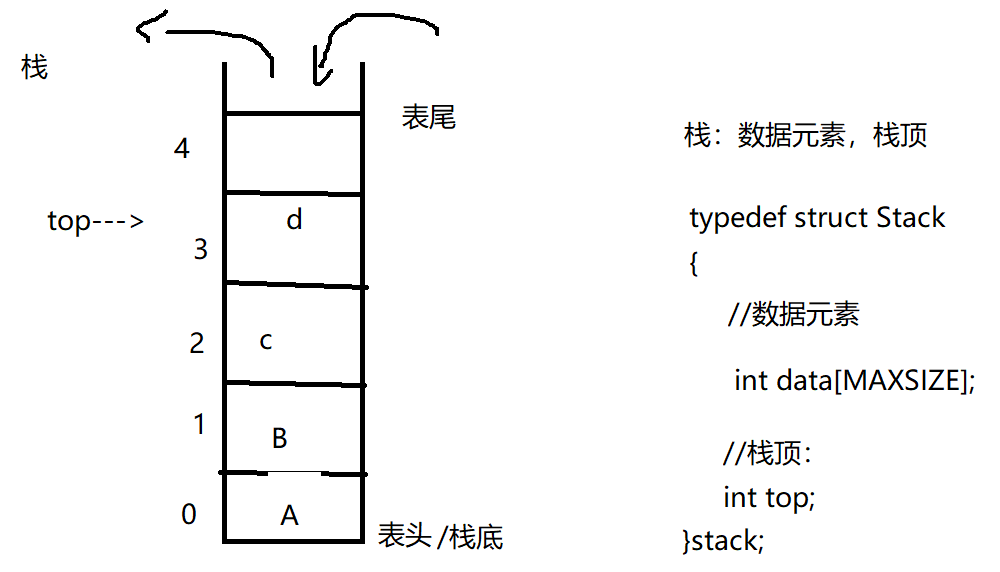
栈:只允许在表尾进行插入和删除的操作受限的线性表
逻辑结构:线性结构(一对一)
存储结构:顺序存储(顺序栈)、链式存储(链栈)
栈的特点:先进后出(first in last out FILO表),后进先出(last in first out LIFO表)
如栈顺序ABC,入栈的过程可以出栈,问有几种情况?
CBA ABC ACB BCA BAC
1>顺序栈
顺序栈:栈借助于顺序存储实现
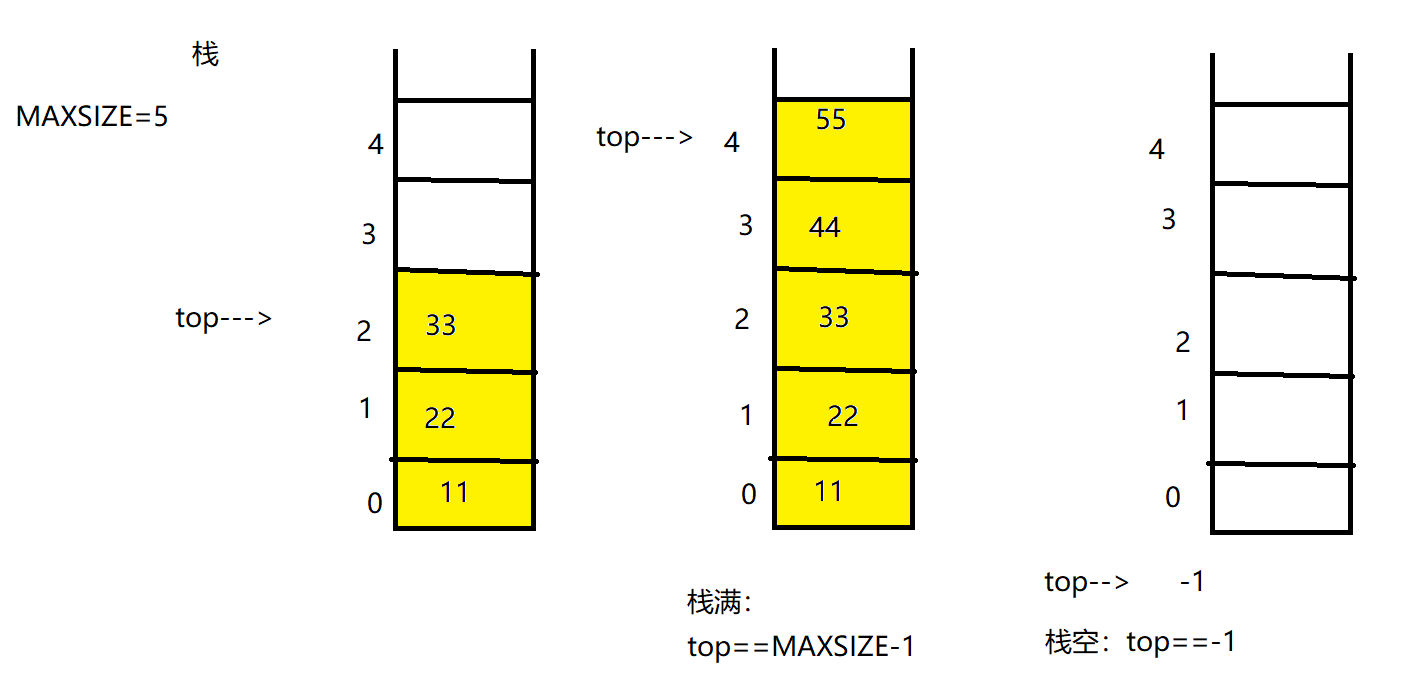
栈的结构体定义:数据元素,栈顶
栈的满:top==MAXSIZE-1
栈空:top==-1
栈顶top:最顶部元素的下表
栈底:下表0
2> 顺序栈的操作
2.1 顺序栈的堆区申请
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 stack create () { stack list =(stack )malloc (sizeof (struct Stacklist)); if (NULL ==list ) return NULL ; memset (list ->data,0 ,sizeof (list ->data)); list ->top=-1 ; return list ; }
2.2 顺序栈的入栈
1 2 3 4 5 6 7 8 9 10 11 12 13 14 int push (stack list ,datatype element) { if (list ->top==MAXSIZE-1 || NULL ==list ) return FALSE; list ->top++; list ->data[list ->top]=element; return SUCCESS; }
2.3 顺序栈的出栈
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 int pop (stack list ) { if (NULL ==list || list ->top==-1 ) return FALSE; printf ("出栈的元素是:%d\n" ,list ->data[list ->top]); list ->top--; return SUCCESS; }
2.4 顺序栈的遍历
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 void output (stack list ) { if (NULL ==list || list ->top==-1 ) return ; for (int i=0 ;i<=list ->top;i++) { printf ("%d " ,list ->data[i]); } puts ("" ); }
3> 链栈
链栈:栈借助于链式存储结构实现
如果链栈的插入删除等于加链表的头插头删,单链表的头等价于栈的栈顶
如果链栈的插入删除等于加链表的尾插尾删,单链表的尾等价于栈的栈顶
八、队列queue
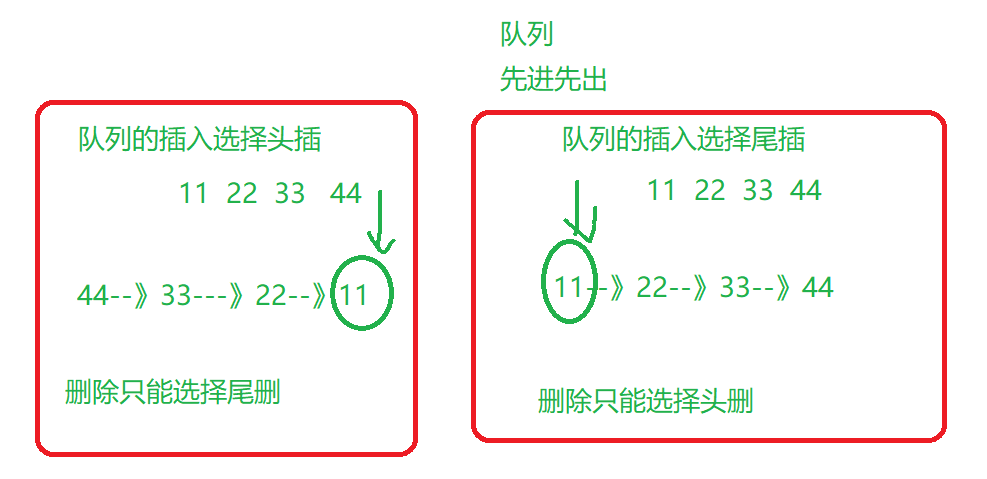
队列:只允许在表尾插入,表头删除的操作受限的线性表
逻辑结构:线性结构(一对一)
存储结构:顺序储存(顺序队列,循环队列),链式存储(链式队列)
队列的特点:先进先出(first in first out FIFO表),后进后出(last in last out LILO表)
1> 顺序队列
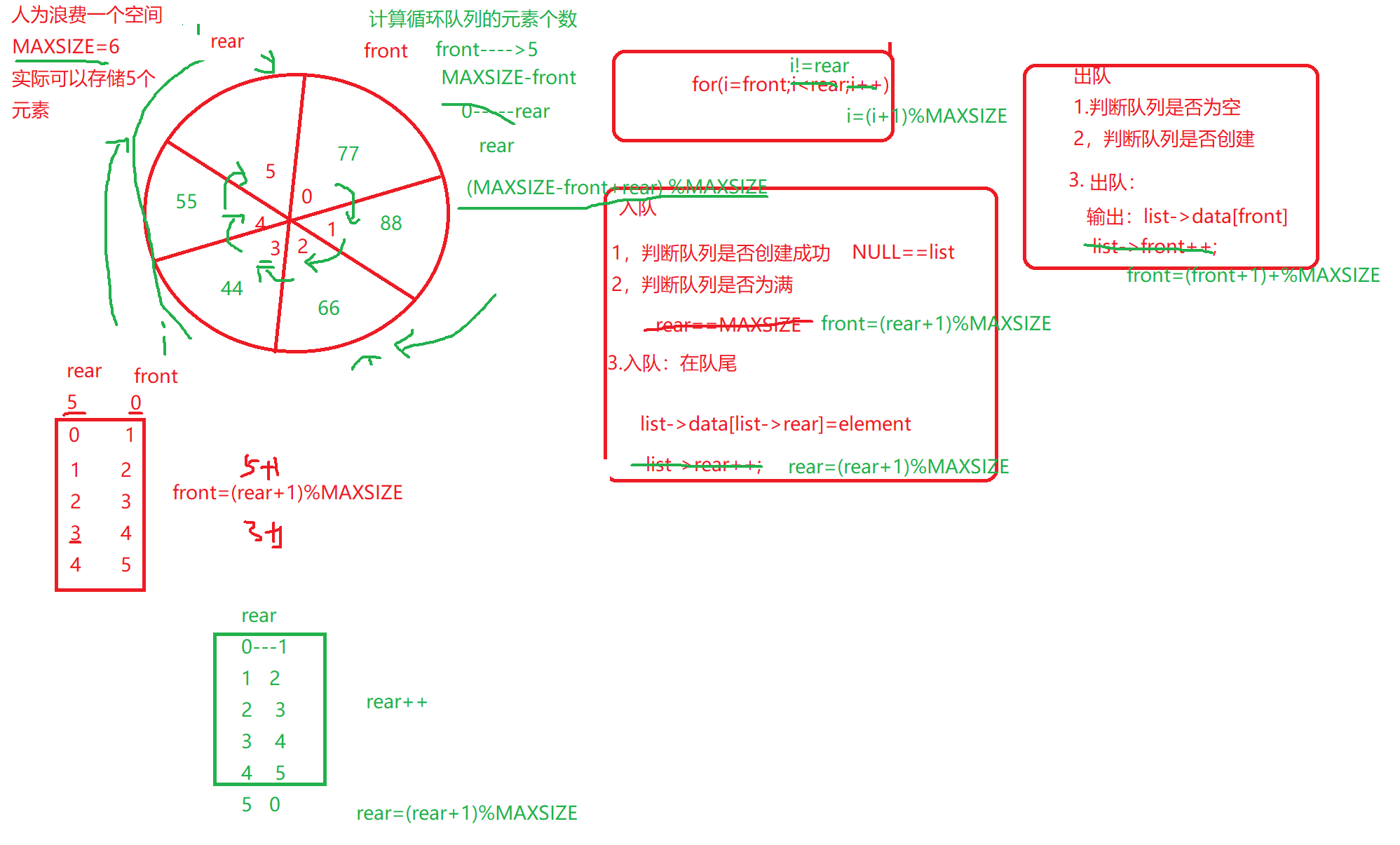
1.1 队头front:第一个数据元素的下表
1.2 队尾rear:最后一个数据元素的下表加1
1.3 队满: rear==MAXSIZE
1.4 队空:front==rear
1.5 定义队列的结构体:数据元素、队头front、队尾rear
1 2 3 4 5 6 7 8 9 typedef struct Q { datatype data[MAXSIZE]; int front; int rear; }*queue ;
2> 循环队列
顺序队列存在假溢出情况,所以引出循环队列用来解决假溢出问题
2.1 循环队列入队
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 int enqueue (queue list ,datatype element) { if (NULL ==list || list ->front==(list ->rear+1 )%MAXSIZE) return FALSE; list ->data[list ->rear]=element; list ->rear=(list ->rear+1 )%MAXSIZE; return SUCCESS; }
2.2 循环队列出队
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 int delqueue (queue list ) { if (NULL ==list || list ->front==list ->rear) return FALSE; printf ("delqueue is %d\n" ,list ->data[list ->front]); list ->front=(list ->front+1 )%MAXSIZE; return SUCCESS; }
2.3 循环队列遍历
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 void output (queue list ) { if (NULL ==list || list ->front==list ->rear) return ; for (int i=list ->front;i!=list ->rear;i=(i+1 )%MAXSIZE) { printf ("%d " ,list ->data[i]); } puts ("" ); }
2.4循环队列计算个数
1 2 3 4 5 6 7 8 9 10 c int length (queue list ) { return (MAXSIZE-list ->front+list ->rear)%MAXSIZE; }
3> 链式队列
循环队列存在队满的情况,适用于数据量较小的时候,那么引出链式队列
存储结构使用链式存储,并且不存在队满的状态。
链式队列的插入和删除等价于单链表的头插尾删,尾插头删
如果队列插入删除选择头插尾删,单链表的头等价于队列的队尾,单链表的尾等价于队列的队头
如果队列插入删除选择尾插头删,单链表的头等价于队列的队头,单链表的尾等价于队列的队尾
4>栈和队列的区别(面试)
1.栈:先进后出 队列:先进先出
2,栈是在一端进行插入和删除 队列是在两端进行插入和删除
3.栈和队列都是操作受限的线性表
九、查找
1> 顺序查找O(n) 例如:顺序表按元素查找
查找是否存在,查找出现的次数,查找存在的下表\位置
2> 折半查找\二分查找O(log2n)
前提条件:查找的序列必须有序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 key=88 1 ----100 50 --100 75 --100 87 --100 int arr[]={12 ,13 ,34 ,56 ,67 ,89 ,109 } int key=100 12 ,13 ,34 ,56 ,67 ,89 ,109 0 1 2 3 4 5 6 l m h 67 ,89 ,109 l m h 109 l h m while (l<=h){ m=(l+h)/2 if (arr[m]< key) { l=m+1 ; } else if (arr[m]>key) { h=m-1 ; } else { m } }
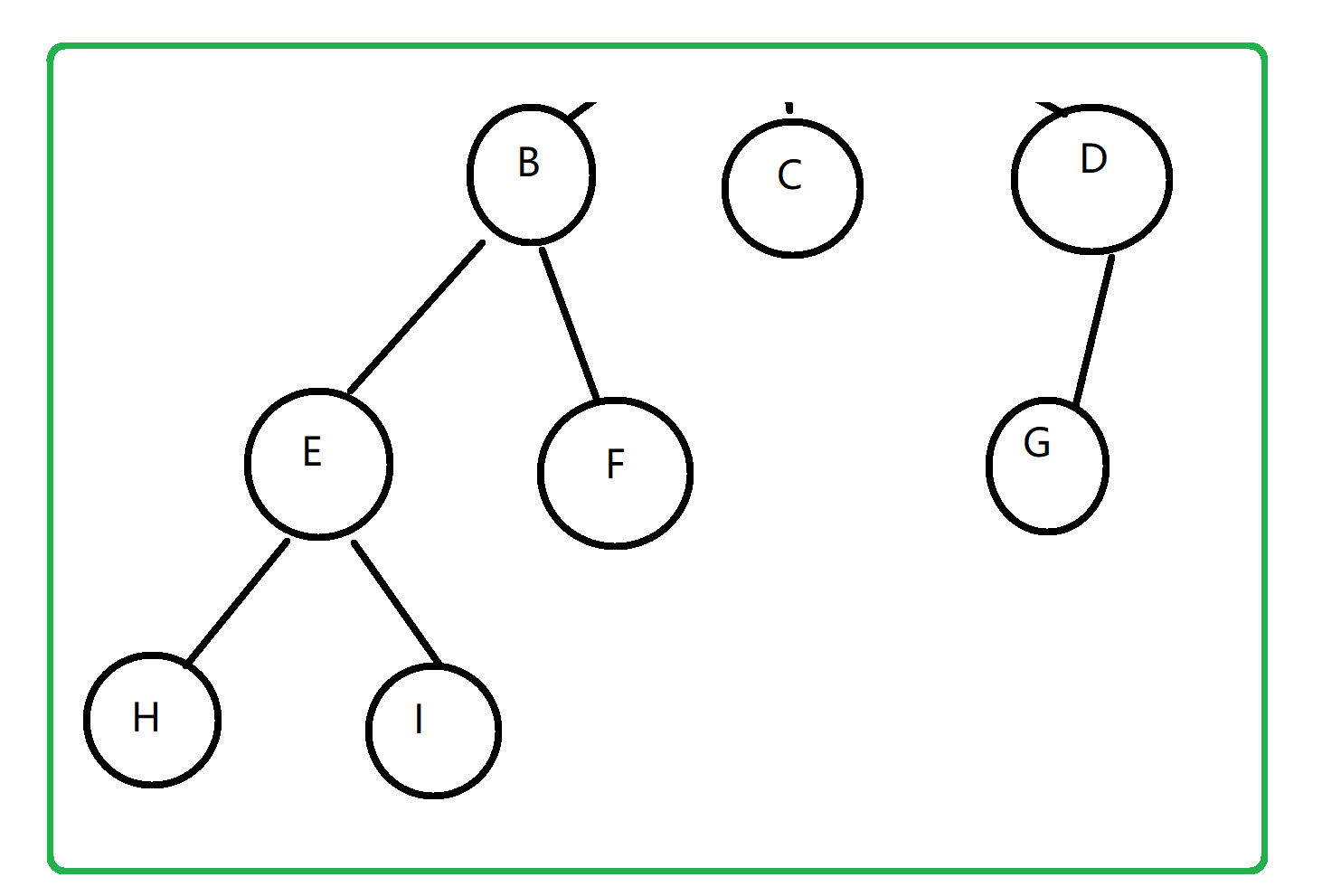
十、树
1.1 树的概念
1>树:
是由根结点和若干棵子树构成的树形结构,是n(n>=0)个结点的有限集,n>0时有且只有一个根结点,除根结点外,其余结点构成的 互不相交 的集合仍是一棵树
2> 空树:
不含任何结点的树n=0
**3>**根结点:
只有一个结点n=1
4> 普通树n>1: 多个结点
4.1有序树 :有序树【从上到下,从左到右】是树中每棵子树从左到右排列有一定顺序,不能互换 的树
4.2>无序树:无序树是树中每棵子树从左到右排列无顺序,能互换 的树
4.3>子树 :是树中一个结点以及其下面所有的结点构成的树
5> 树的类型
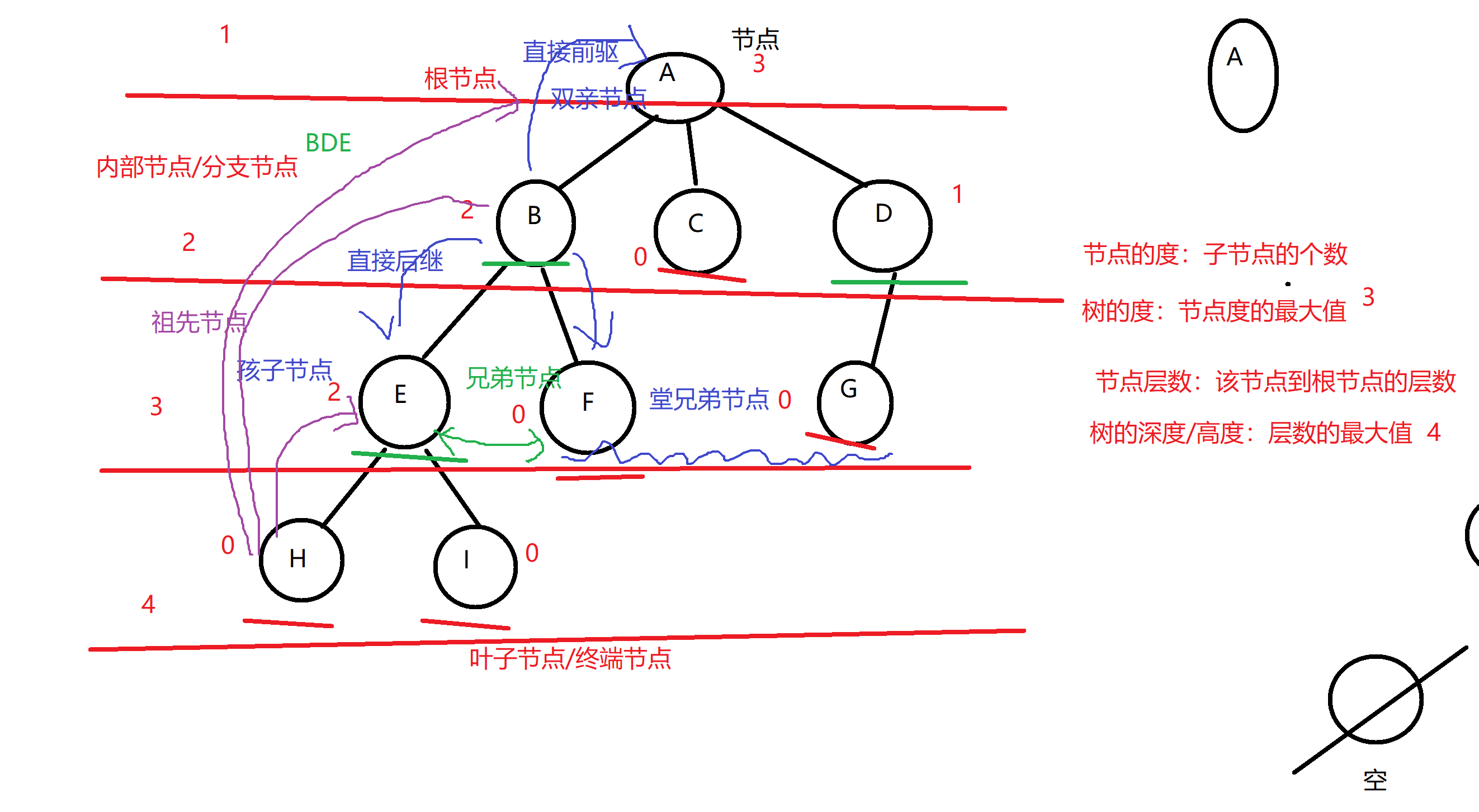
结点 :树中的数据元素结点的度 :结点含有子树的个数根结点 :没有双亲结点【前驱】的结点分支结点(内部结点) :是度不为0的结点叶结点(终端结点) :是度为0的结点结点的层数 :是从根结点到某结点所路径上的层数【根结点表示第一层】树的深度(高度) :是树中所有结点层数的最大值树的度 :各结点度的最大值
6> 结点之间的关系
父结点 :是指当前结点的直接上级结点孩子结点 :是指当前结点的直接下级结点兄弟结点 :是由相同父结点的结点祖先结点 :是当前结点的直接及间接上级结点子孙结点 :是当前结点直接及间接下级结点堂兄弟结点 :是父结点在同一层的结点
7> 森林
森林 :是指0个或多个互不相交 树的集合
1.2 二叉树概念
1 二叉树的概念
二叉树:树的度小于等于2
1>二叉树是每个结点最多有左、右两棵子树且严格区分顺序的树形结构【二叉树不可以互换】
2>二叉树的左边:左子树是以当前结点的左孩子结点作为根节点的子树
3>二叉树的右边:右子树是以当前结点的右孩子结点作为根节点的子树
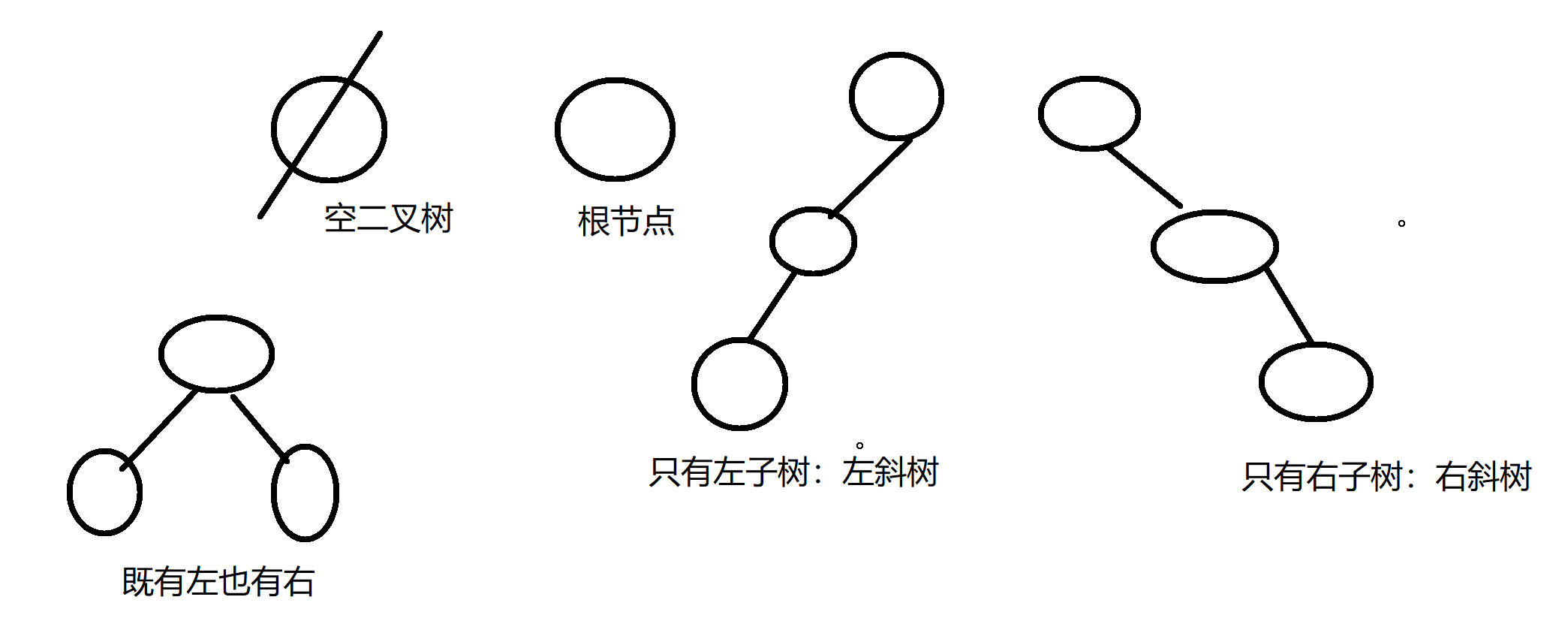
2 二叉树的特殊形态
空二叉树
只有一个根节点
只有左子树
只有右子树
既有左子树又有右子树
3 二叉树的类型
1>空二叉树 :空二叉树是没有结点的二叉树
2>斜树 :斜树是所有的结点都只有左子树或者都只有右子树的二叉树
2.1 左斜树:左斜树是所有的结点都只有左子树的斜树
2.2右斜树:右斜树是所有的结点都只有右子树的斜树
n个节点,斜树是最高的二叉树
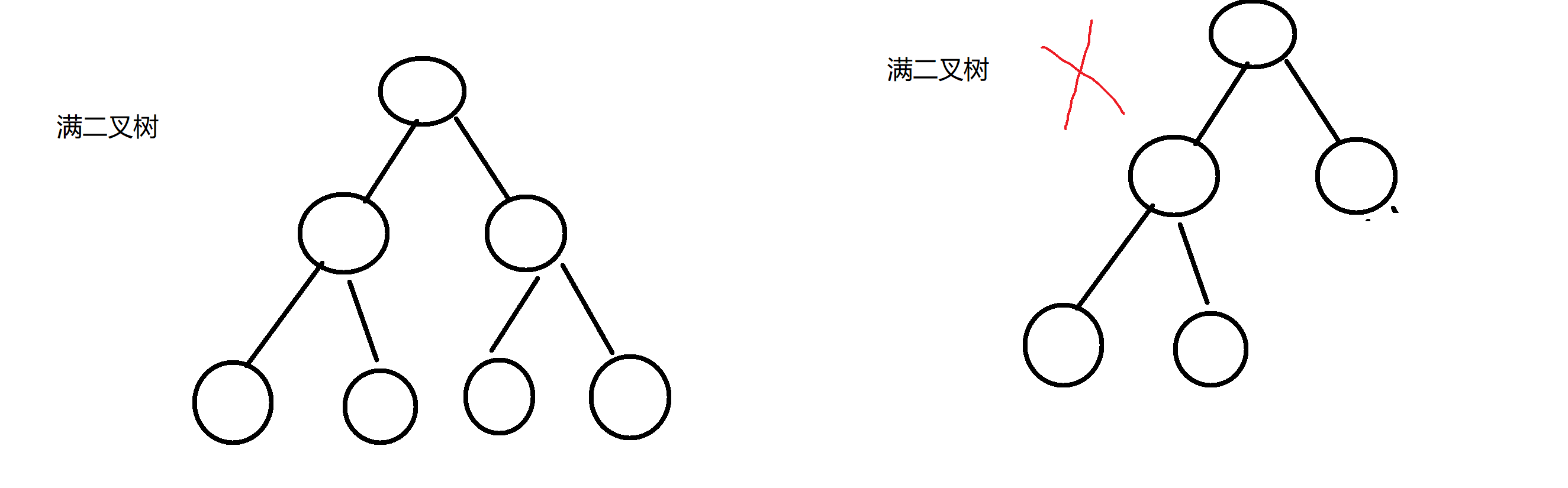
3>满二叉树 :满二叉树是最后一层是叶子结点,其余结点度是2的二叉树
(1)叶子结点只能出现在最下面一层
(2)非叶子结点的度数一定是2
(3)同样深度的二叉树中,满二叉树的结点的个数最多,叶子结点最多
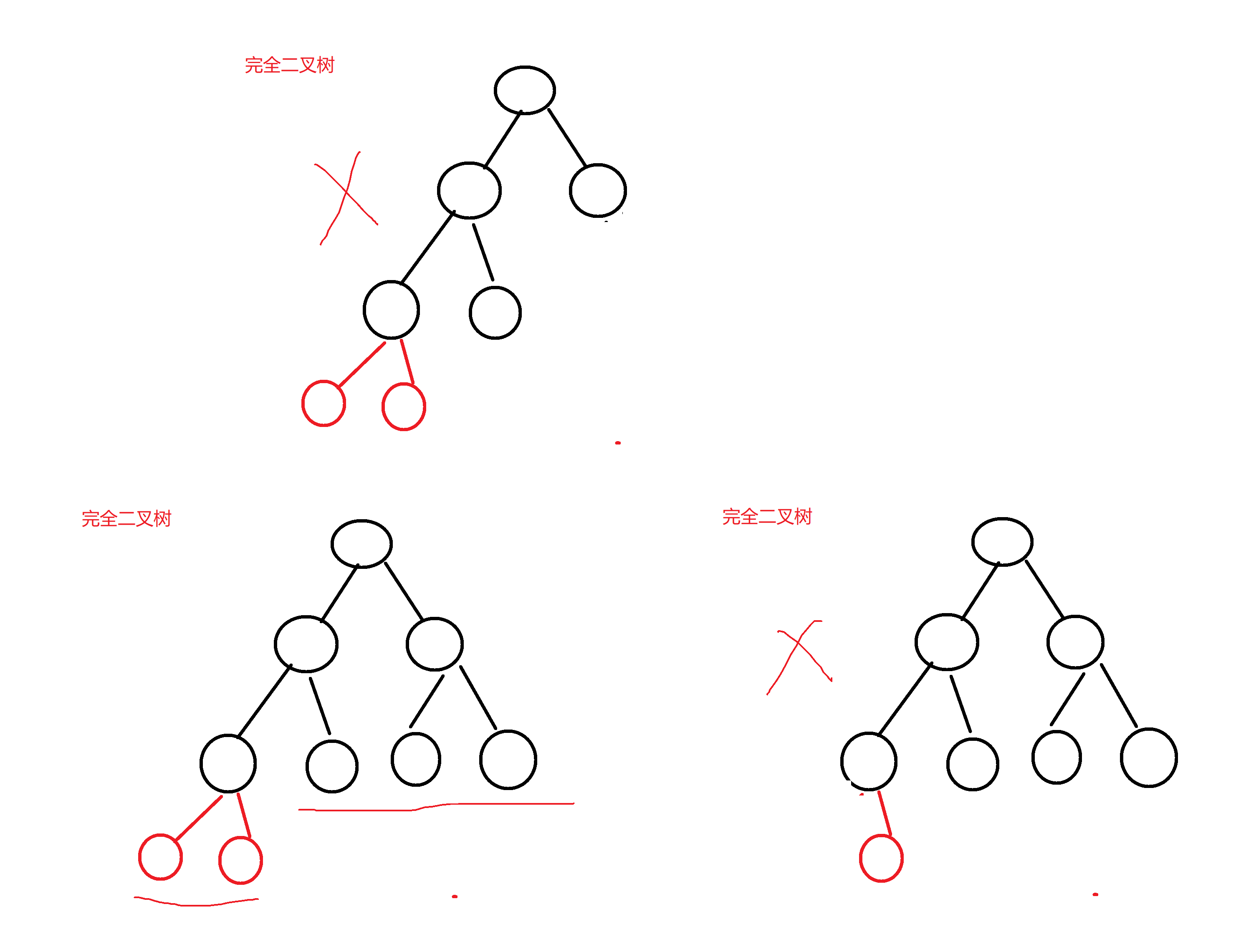
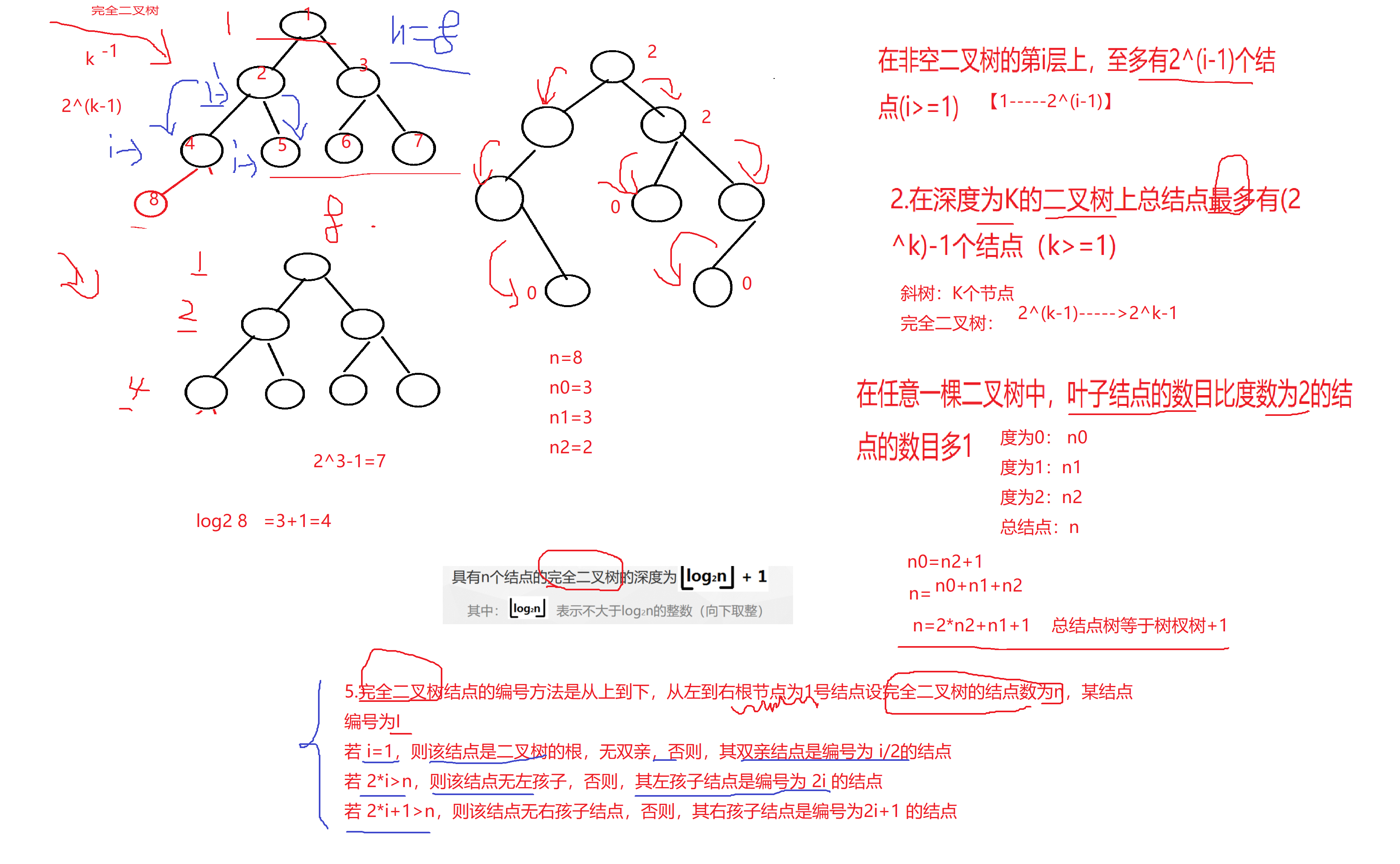
4>完全二叉树 :完全二叉树是在一棵满二叉树基础上自左向右连续增加叶子结点得到的二叉树
(1)只有最后两层有叶子结点
(2)除最后一层是一棵满二叉树
(3)最后一层的叶子结点集中在左边连续的位置
满二叉树一定是完全二叉树,完全二叉树不一定是满二叉树
4 二叉树的性质
1.在非空二叉树的第i层上,至多有2^(i-1)个结点(i>=1)
[1,2^(i-1)]
2.在深度为K的二叉树上总结点最多有(2^k)-1个结点(k>=1)
深度为K的二叉树最少右k个节点,例如斜树
完全二叉树的节点[2(k-1),(2 k)-1]
3.在任意一棵二叉树中,叶子结点的数目比度数为2的结点的数目多1
度为0:n0 度为1:n1 度为2:n2
n0=n2+1
总节点:n=n0+n1+n2
总结点数=树杈树+1
=2*n2+n1+1
5.完全二叉树结点的编号方法是从上到下,从左到右根节点为1号结点设完全二叉树的结点数为n,某结点编号为I
若 i=1,则该结点是二叉树的根,无双亲,否则,其双亲结点是编号为 i/2的结点
若 2*i>n,则该结点无左孩子,否则,其左孩子结点是编号为 2i 的结点
若 2*i+1>n,则该结点无右孩子结点,否则,其右孩子结点是编号为2i+1 的结点
n=n0+n1+n2+n3
n=32+2 1+1*2+1=11
11=n0+2+1+2
n0=6
n=n0+n1+n2+n3+n4
19=n0+4+2+2+1 n0=10
n=4+22+3 2+4*1+1=19
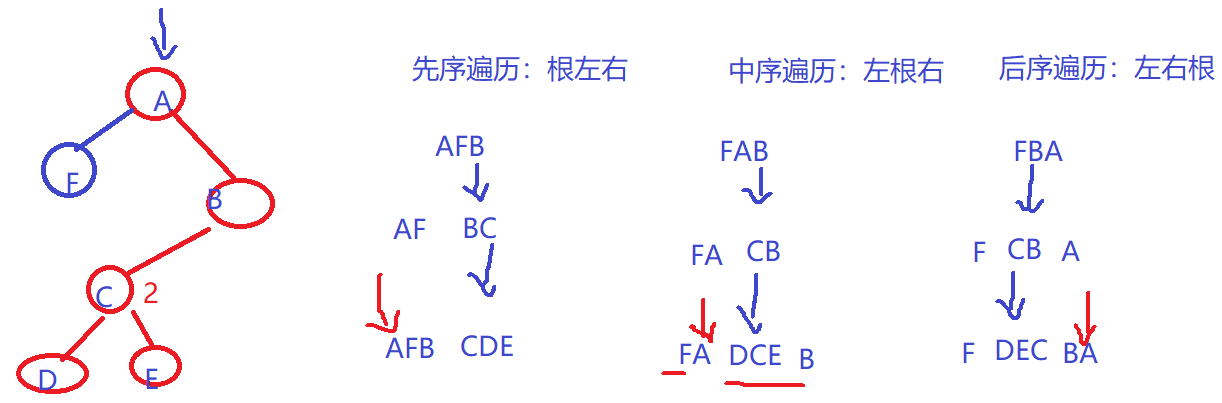
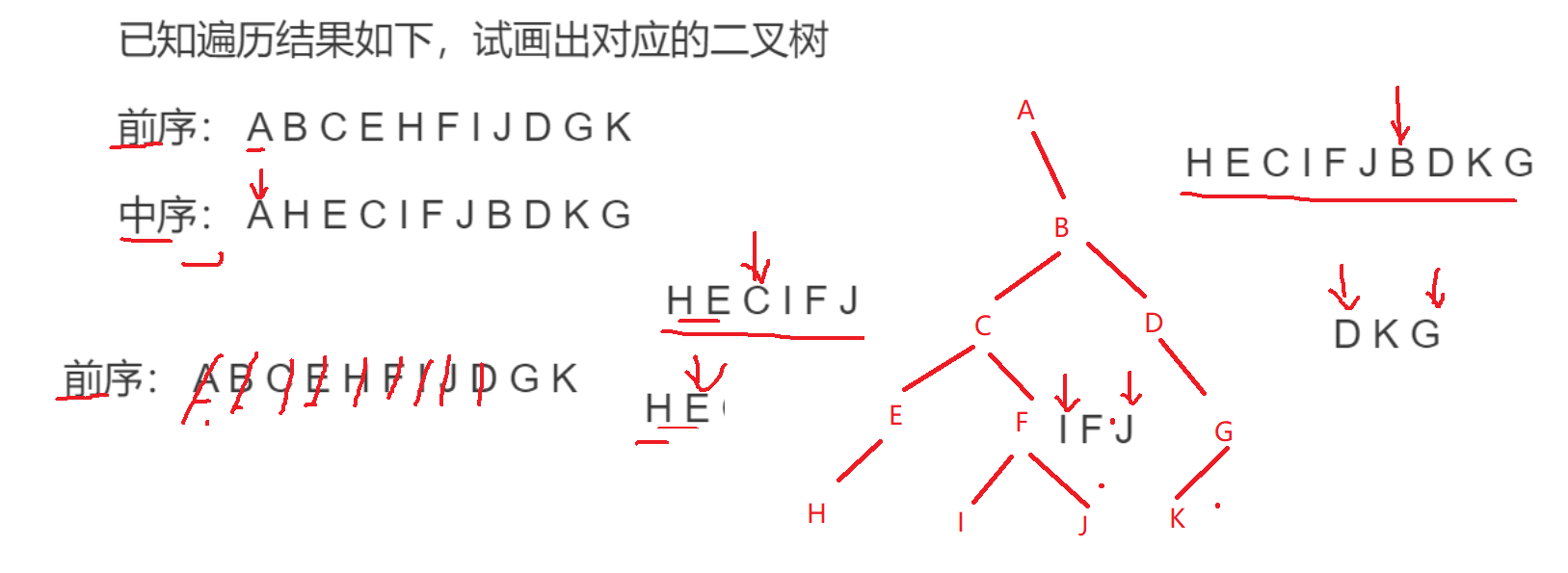
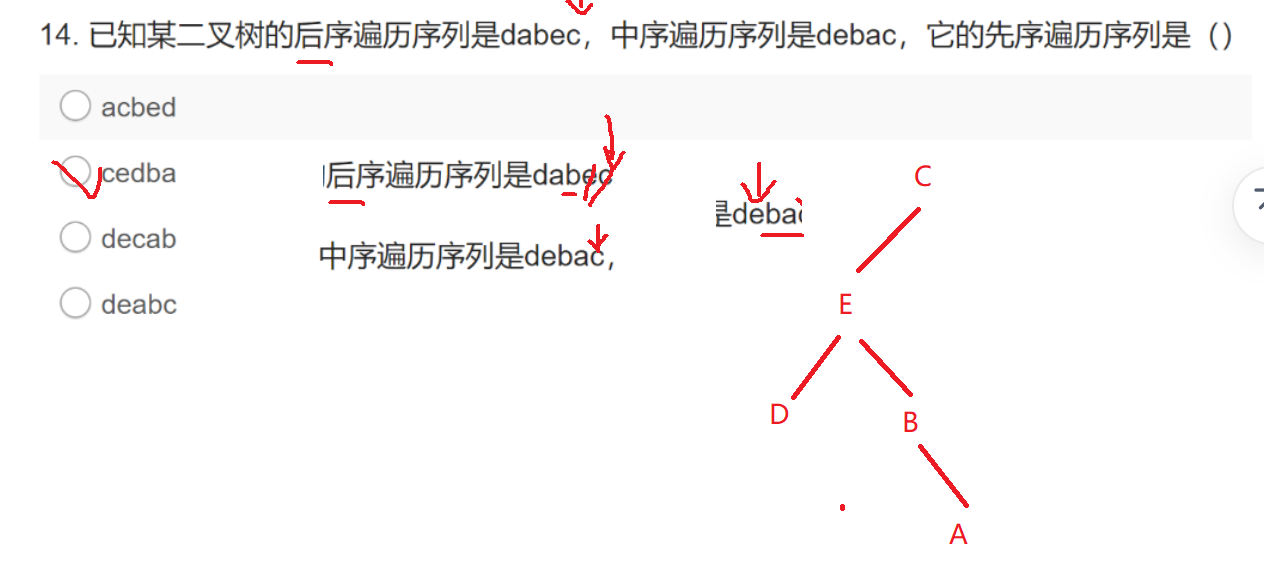
4.4二叉树遍历
先序遍历:按照根 左右的顺序
中序遍历:按照左根 右的顺序
后序遍历:按照左右根 的顺序
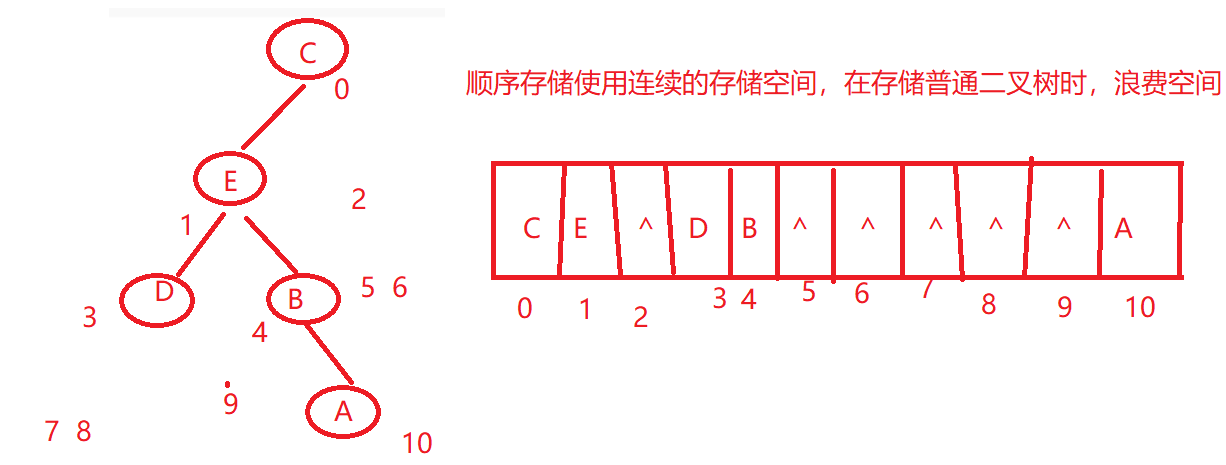
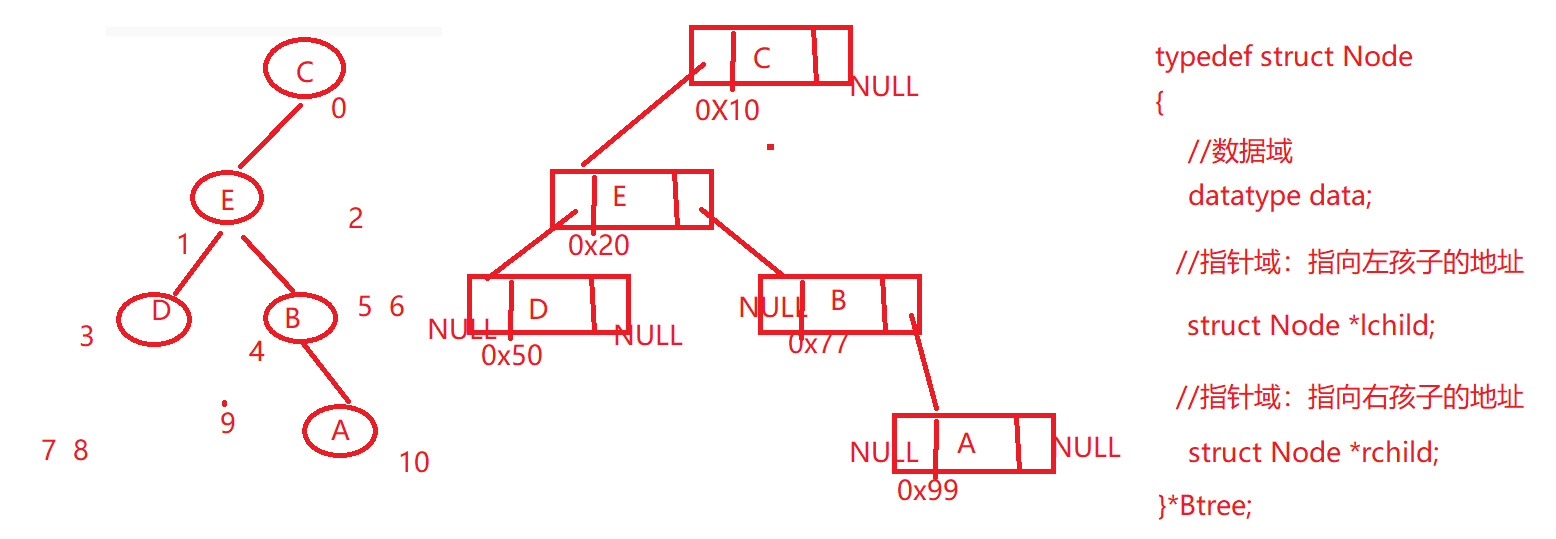
4.3 二叉树的存储形式
i> 顺序存储
ii> 链式存储
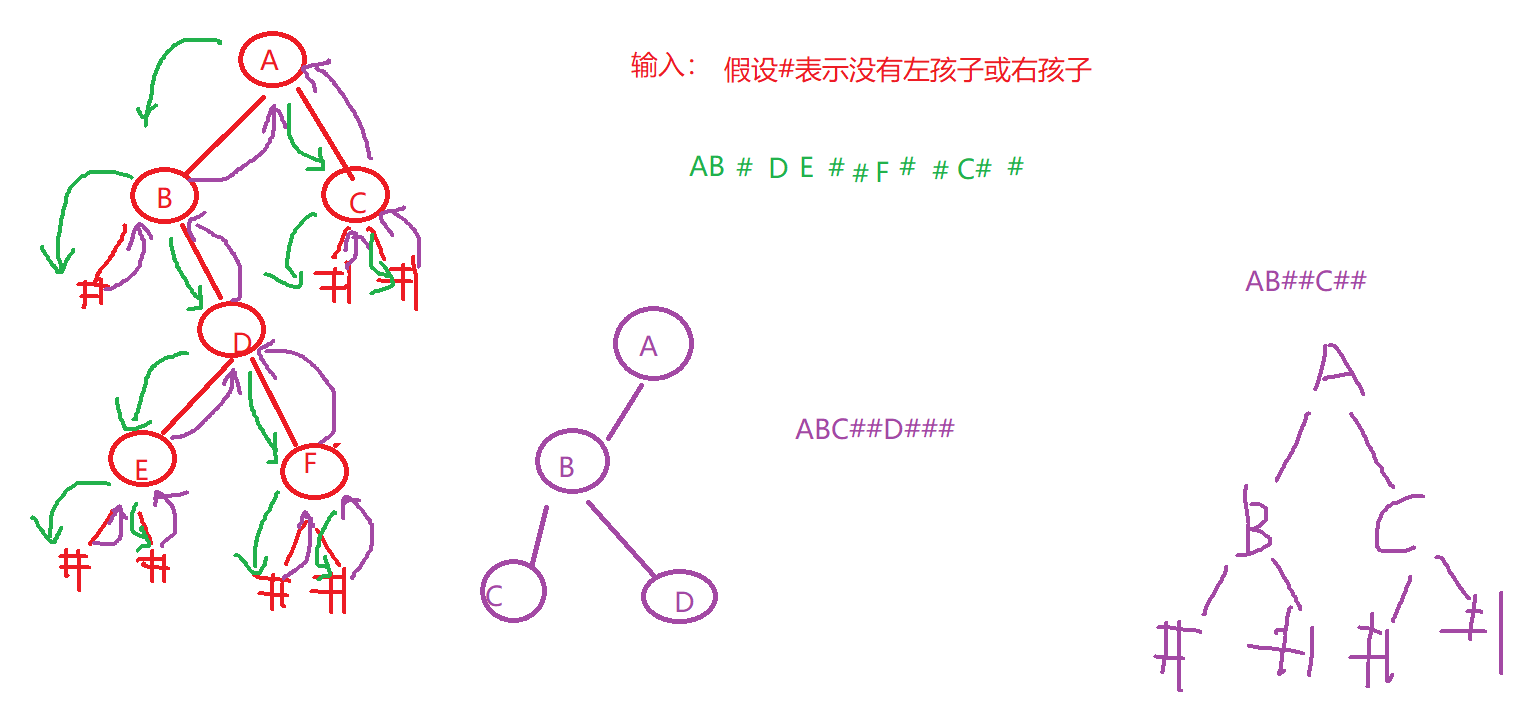
4.5 二叉树输入和还原
先左后右
4.6 二叉树的操作
i> 二叉树的创建
Plain Text
自动换行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 Btree create_node () { Btree p=(Btree)malloc (sizeof (struct Node)); if (NULL ==p) return NULL ; p->data='\0' ; p->lchild=NULL ; p->rchild=NULL ; return p; } Btree create_tree () { datatype element; printf ("please enter element:" ); scanf (" %c" ,&element); if (element=='#' ) return NULL ; Btree tree=create_node(); tree->data=element; tree->lchild=create_tree(); tree->rchild=create_tree(); return tree; }
ii> 二叉树先序遍历
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void first_output (Btree tree) { if (tree==NULL ) return ; printf ("%c " ,tree->data); first_output(tree->lchild); first_output(tree->rchild); }
iii>二叉树中序遍历
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void mid_output (Btree tree) { if (tree==NULL ) return ; mid_output(tree->lchild); printf ("%c " ,tree->data); mid_output(tree->rchild); }
iv> 二叉树后序遍历
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void last_output (Btree tree) { if (tree==NULL ) return ; last_output(tree->lchild); last_output(tree->rchild); printf ("%c " ,tree->data); }
v>二叉树计算各个节点的个数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 void Count (Btree tree,int *n0,int *n1,int *n2) { if (tree==NULL ) return ; if (tree->lchild==NULL && tree->rchild==NULL ) ++*n0; else if (tree->lchild!=NULL && tree->rchild!=NULL ) ++*n2; else ++*n1; Count(tree->lchild,n0,n1,n2); Count(tree->rchild,n0,n1,n2); }
vi>二叉树计算深度
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 int length (Btree tree) { if (tree==NULL ) return 0 ; int left=length(tree->lchild)+1 ; int right=length(tree->rchild)+1 ; return left>right?left:right; }
vii>二叉树的释放
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 void free_space (Btree tree) { if (NULL ==tree) return ; free_space(tree->lchild); free_space(tree->rchild); free (tree); tree=NULL ; }
二、哈希表
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数 ,存放记录的数组叫做散列表 。给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希(Hash)表,函数f(key)为哈希(Hash) 函数。(例如词典)
i> 哈希函数
直接定址法:取关键字或关键字的某个线性函数值为哈希地址的方法
线性函数:f(x) = ax+b,其中a和b为常数
数字分析法:通过分析取关键字的若干数位组成哈希地址的方法
平方取中法:取关键字平方后的中间几位数组成哈希地址的方法
除留余数法:取关键字被某个不大于哈希表表长m的数p除后所得余数为哈希地址的方法
H(key)=key MOD p (p<=m)
p一般取不大于表长m的最大质数(素数,只能被1和本身整除)
m:哈希表长,数组长度除以3/4
ii> 哈希冲突
哈希冲突:不同的关键字通过哈希函数映射在计算机的同一个存储位置,称为冲突
1、开放定址法
i>线性探测法:di=1,2,3,…,m-1,即从冲突地址向后依次查找空闲地址的处理冲突方法
ii>二次探测法:di=1^2,- 1^2 ,22,-2 2,32,…,±k 2,(k≤m/2)即从冲突地址向前后 以整数二次方为增量查找空闲地址的处理冲突方法
iii>伪随机探测法:di为确定的伪随机数序列(如3,5,8…),即将冲突地址加上序列中的伪随机 数以查找空地址的处理冲突方法
2、再哈希法:在发生冲突时使用另一个哈希函数计算地址,直到不再发生冲突
3、链地址法:将所有哈希函数值相同的记录存储在同一线性链表中
4、建立公共溢出区:一旦发生冲突,都填入溢出表
iii>哈希表功能实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 #include <stdio.h> #include <string.h> #include <stdlib.h> #include <math.h> typedef struct Node { int data; struct Node *next ; }*node; int Prime (int m) { for (int i=m;i>=2 ;i--) { int flag=1 ; for (int j=2 ;j<=sqrt (i);j++) { if (i%j==0 ) { flag=0 ; break ; } } if (flag==1 ) return i; } } node create_node () { node s=(node)malloc (sizeof (struct Node)); if (NULL ==s) return NULL ; s->data=0 ; s->next=NULL ; return s; } void insert_hash (node hash[],int key,int p) { int index=key%p; node s=create_node(); if (NULL ==s) return ; s->data=key; if (hash[index]==NULL ) hash[index]=s; else { s->next=hash[index]; hash[index]=s; } } void output (node hash[],int m) { for (int i=0 ;i<m;i++) { printf ("%d:" ,i); node q=hash[i]; while (q!=NULL ) { printf ("%-4d" ,q->data); q=q->next; } puts ("NULL" ); } } int search_hash (node hash[],int key,int p) { int index=key%p; node q=hash[index]; if (q==NULL ) return -1 ; while (q!=NULL ) { if (q->data==key) return 0 ; q=q->next; } return -1 ; } int main (int argc, const char *argv[]) { int arr[]={41 ,54 ,67 ,25 ,51 ,8 ,22 ,26 ,11 ,16 }; int len=sizeof (arr)/sizeof (arr[0 ]); int m=len*4 /3 ; int p=Prime(m); node hash[m]; for (int i=0 ;i<m;i++) { hash[i]=NULL ; } for (int i=0 ;i<len;i++) { insert_hash(hash,arr[i],p); } output(hash,m); int key; printf ("plase enter key:" ); scanf ("%d" ,&key); int flag=search_hash(hash,key,p); if (flag==-1 ) puts ("unexists" ); else puts ("exists" ); return 0 ; }
三、排序算法
排序算法:把无序序列转换为有序序列的一种排序
内排:在计算机内存实现的排序算法(适用于数据量较小的情况)
外排:在计算内存和外部介质实现的排序算法(先内在外,适用于数据量较大的情况)
排序算法分类:
交换排序:冒泡排序、快速排序
选择排序:简单选择,堆排序
插入排序:直接插入排序,希尔排序
归并排序:二路归并(内+外),多路归并(外)
基数排序
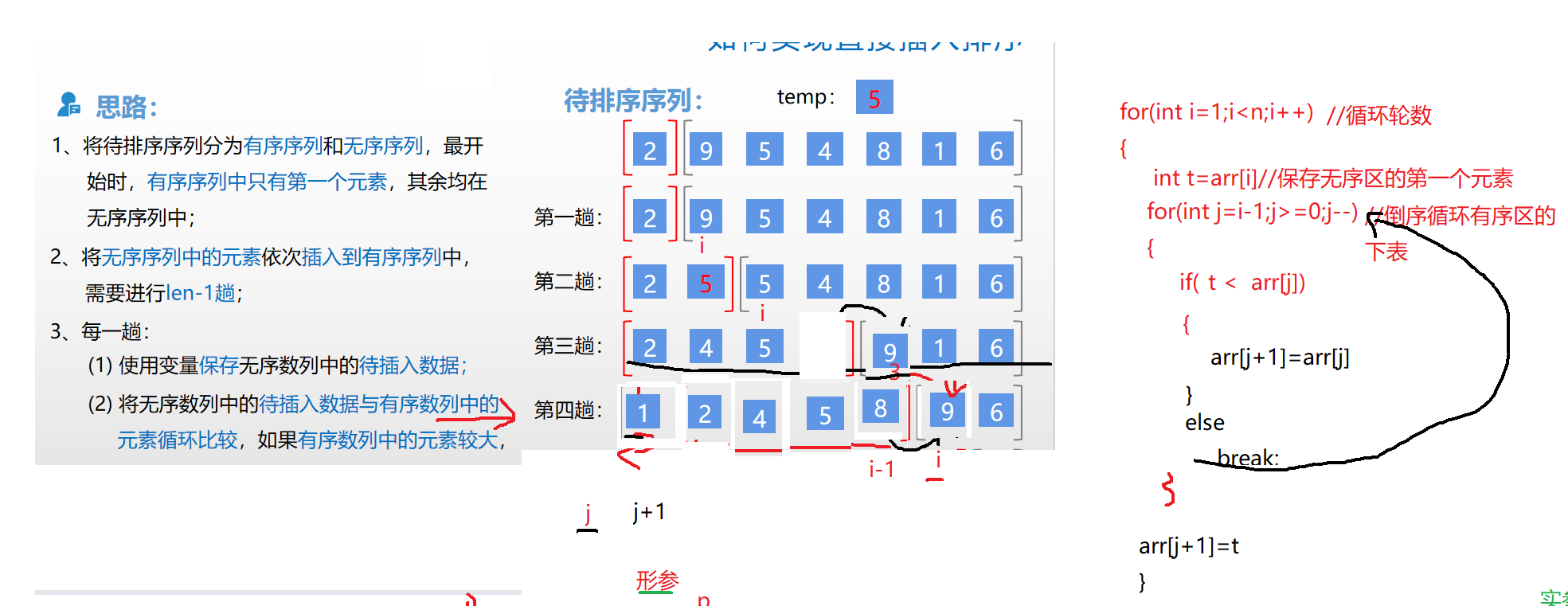
1.插入排序:
插入排序:把无序序列分成有序区和无序区,依次拿无序区的每一个元素依次插入有序区中,经过大小比较实现后移,插入到合适的位置,直至序列有序。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 int main (int argc, const char *argv[]) { int arr[]={12 ,234 ,1 ,235 ,12 ,5 }; int len=sizeof (arr)/sizeof (arr[0 ]); int j; for (int i=1 ;i<len;i++) { int t=arr[i]; for (j=i-1 ;j>=0 ;j--) { if (t <arr[j]) { arr[j+1 ]=arr[j]; } else break ; } arr[j+1 ]=t; } for (int i=0 ;i<len;i++) { printf ("%d " ,arr[i]); } return 0 ; }
2.快速排序
快速排序:从无序序列中找基准值(默认第一个),大于基准值或小于放前边,小于或大于基准值放在后边,
确定基准值的位置,通过基准值把待排序列分成左右两部分,重复以上过程,直至序列为有序序列。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 #include <stdio.h> #include <string.h> #include <stdlib.h> int once_sort (int arr[],int low,int high) { int key=arr[low]; while (low<high) { while (low<high&&key <=arr[high]) { high--; } arr[low]=arr[high]; while (low<high&&key>=arr[low]) { low++; } arr[high]=arr[low]; } arr[low]=key; return low; } void quick_sort (int arr[],int low,int high) { if (low>=high) return ; int mid=once_sort(arr,low,high); quick_sort(arr,low,mid-1 ); quick_sort(arr,mid+1 ,high); } int main (int argc, const char *argv[]) { int arr[]={12 ,345 ,12 ,35 ,3 ,565 ,3 }; int len=sizeof (arr)/sizeof (arr[0 ]); quick_sort(arr,0 ,len-1 ); for (int i=0 ;i<len;i++) { printf ("%d " ,arr[i]); } return 0 ; }
3.排序算法的总结
排序分类
排序名称
时间复杂度
稳定性
交换排序
冒泡排序
O(n^2)
稳定
选择排序
简单选择排序
O(n^2)
不稳定
插入排序
插入排序
O(n^2)
稳定
交换排序
快速排序
O(nlog2n)
不稳定
插入排序
希尔排序
O(n^1.5)
不稳定
归并排序
二路归并
O(nlog2n)
稳定
重点
1.内存
2.动态申请和释放malloc free
3.野指针
4.宏:宏函数,简单宏
5.typedef 和宏的区别
6.结构体:字节大小、 结构体位域:字节大小的计算
7.顺序表和链表的区别
8.顺序表:插入和删除
9.链表:头插、头删、尾插、尾删
逆置、查找倒数第n、排序
11队列:循环队列
12.查找:二分查找
13.排序:插入排序,快速排序
14.二叉树:创建、遍历、各个节点的个数,深度